I'm using SQL Server 2008. I have a table with over 3 million records, which is related to another table with a million records.
I have spent a few days experimenting with different ways of querying these tables. I have it down to two radically different queries, both of which take 6s to execute on my laptop.
The first query uses a brute force method of evaluating possibly likely matches, and removes incorrect matches via aggregate summation calculations.
The second gets all possibly likely matches, then removes incorrect matches via an EXCEPT query that uses two dedicated indexes to find the low and high mismatches.
Logically, one would expect the brute force to be slow and the indexes one to be fast. Not so. And I have experimented heavily with indexes until I got the best speed.
Further, the brute force query doesn't require as many indexes, which means that technically it would yield better overall system performance.
Below are the two execution plans. If you can't see them, please let me know and I'll re-post then in landscape orientation / mail them to you.
Brute-force query:
SELECT ProductID, [Rank]
FROM (
SELECT p.ProductID, ptr.[Rank], SUM(CASE
WHEN p.ParamLo < si.LowMin OR
p.ParamHi > si.HiMax THEN 1
ELSE 0
END) AS Fail
FROM dbo.SearchItemsGet(@SearchID, NULL) AS si
JOIN dbo.ProductDefs AS pd
ON pd.ParamTypeID = si.ParamTypeID
JOIN dbo.Params AS p
ON p.ProductDefID = pd.ProductDefID
JOIN dbo.ProductTypesResultsGet(@SearchID) AS ptr
ON ptr.ProductTypeID = pd.ProductTypeID
WHERE si.Mode IN (1, 2)
GROUP BY p.ProductID, ptr.[Rank]
) AS t
WHERE t.Fail = 0

Index-based exception query:
with si AS (
SELECT DISTINCT pd.ProductDefID, si.LowMin, si.HiMax
FROM dbo.SearchItemsGet(@SearchID, NULL) AS si
JOIN dbo.ProductDefs AS pd
ON pd.ParamTypeID = si.ParamTypeID
JOIN dbo.ProductTypesResultsGet(@SearchID) AS ptr
ON ptr.ProductTypeID = pd.ProductTypeID
WHERE si.Mode IN (1, 2)
)
SELECT p.ProductID
FROM dbo.Params AS p
JOIN si
ON si.ProductDefID = p.ProductDefID
EXCEPT
SELECT p.ProductID
FROM dbo.Params AS p
JOIN si
ON si.ProductDefID = p.ProductDefID
WHERE p.ParamLo < si.LowMin OR p.ParamHi > si.HiMax
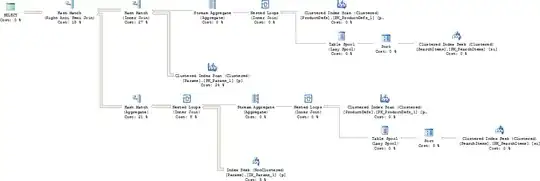
My question is, based on the execution plans, which one look more efficient? I realize that thing may change as my data grows.
EDIT:
I have updated the indexes, and now have the following execution plan for the second query:
