I set a dataframe using the following code:
df = pd.DataFrame({'A':['a','a','b','c'],'B':[123,456,555,888]})
I then execute the following code:
pd.pivot(df.A, df.index, df.B)
The dataframe changes to this:
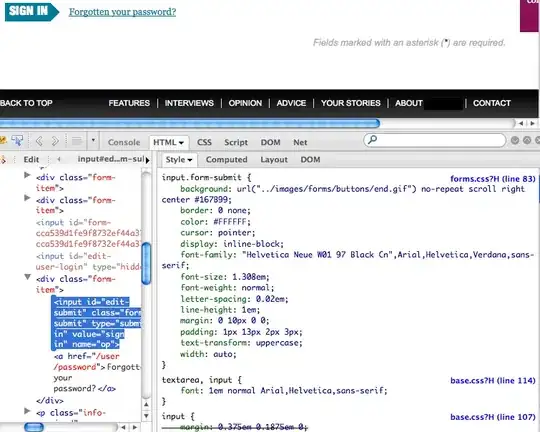
Now I want to know how to move non-NAN values to the front columns like this: