I'm looking for the implementation of pow(real, real) in x86 Assembly. Also I'd like to understand how the algorithm works.
Asked
Active
Viewed 3.2k times
37
jv110
- 353
- 2
- 13
Maciej Ziarko
- 11,494
- 13
- 48
- 69
-
glibc's implementation of the `pow()` function is [in sysdeps/ieee754/dbl-64/e_pow.c](http://repo.or.cz/glibc.git/blob/HEAD:/sysdeps/ieee754/dbl-64/e_pow.c). It uses some some integer examination of the FP bit patterns, and some FP multiplies and adds, but doesn't use any special x87 instructions. For x86-64, it gets compiled into `__ieee754_pow_sse2()` ([by this code that #includes it](http://repo.or.cz/glibc.git/blob/455d6e4373c81da49892d39f33dc312b0c54097d:/sysdeps/x86_64/fpu/multiarch/e_pow.c)). Anyway, x87 isn't the best way to do it on modern CPUs. – Peter Cordes Sep 19 '16 at 02:28
-
I assume glibc's code is either more accurate or faster than x87. Possibly both, but maybe just more accurate (correctly rounded to nearest). It doesn't use a loop, though, and single-stepping through the instructions, there aren't *that* many for `pow(1.175, 33.75)`. FYL2X is a very slow instruction (~100 cycles) on modern CPUs, so it shouldn't be that hard to beat it. – Peter Cordes Sep 19 '16 at 02:30
-
Related: [Optimizations for pow() with const non-integer exponent?](//stackoverflow.com/q/6475373) has a fast approximate version (using SIMD intrinsics). See also [Where is Clang's '\_mm256\_pow\_ps' intrinsic?](//stackoverflow.com/q/36636159) for SIMD math libraries that provide `pow`. – Peter Cordes Jul 28 '19 at 22:24
3 Answers
68
Just compute it as 2^(y*log2(x)).
There is a x86 instruction FYL2X to compute y*log2(x) and a x86 instruction F2XM1 to do exponentiation. F2XM1 requires an argument in [-1,1] range, so you'd have to add some code in between to extract the integer part and the remainder, exponentiate the remainder, use FSCALE to scale the result by an appropriate power of 2.
Eugene Smith
- 9,126
- 6
- 36
- 40
-
6I know this is an old thread, but here's an implementation: [madwizard.org](http://www.madwizard.org/programming/snippets?id=36) – Matth Apr 09 '16 at 20:27
-
2Just to have code here: `fld power` `fld x` `fyl2x` `fld1` `fld st(1)` `fprem` `f2xm1` `fadd` `fscale` `fxch st(1)` `fstp st` `;st0 = X^power` – Qwertiy Jul 28 '19 at 18:35
16
OK, I implemented power(double a, double b, double * result); in x86 just as you recommended.
Code: http://pastebin.com/VWfE9CZT
%define a QWORD [ebp+8]
%define b QWORD [ebp+16]
%define result DWORD [ebp+24]
%define ctrlWord WORD [ebp-2]
%define tmp DWORD [ebp-6]
segment .text
global power
power:
push ebp
mov ebp, esp
sub esp, 6
push ebx
fstcw ctrlWord
or ctrlWord, 110000000000b
fldcw ctrlWord
fld b
fld a
fyl2x
fist tmp
fild tmp
fsub
f2xm1
fld1
fadd
fild tmp
fxch
fscale
mov ebx, result
fst QWORD [ebx]
pop ebx
mov esp, ebp
pop ebp
ret
Maciej Ziarko
- 11,494
- 13
- 48
- 69
-
4Could I recommend that you go ahead and include that code here, in your answer? – Jonathon Reinhart Jun 04 '12 at 19:29
-
2You should `sub esp, 8` to keep it aligned for pushing ebx. You could also swap tmp and ControlWord, e.g. `%define tmp DWORD [ebp-4]`, so it's aligned. – Peter Cordes Sep 18 '16 at 22:40
-
It would make a lot more sense to return a `double` instead of taking an output arg, so you can just leave the value in `st0`. Or if you insist on taking a pointer, load the pointer into EAX, ECX, or EDX so you don't have to save/restore EBX at all. Also, you should restore the original rounding mode when you're done. (e.g. save the original in a register, then store and `fldcw` it). This leaves it set to truncation (toward zero), not the default round-to-nearest. http://www.efg2.com/Lab/Library/Delphi/MathFunctions/FPUControlWord.Txt. – Peter Cordes Apr 02 '19 at 01:52
-
Update: `frndint` is slow on a lot of CPUs (https://agner.org/optimize/), so `fist`/`fild` is actually better. And if you want to convert with truncation, you can use [SSE3 `fisttp`](https://www.felixcloutier.com/x86/fisttp) if available instead of changing the FP rounding mode and restoring it. Or just use SSE2 `cvttsd2si` to convert with truncation. – Peter Cordes Jul 28 '19 at 22:28
3
Here's my function using the main algorithm by 'The Svin'. I wrapped it in __fastcall & __declspec(naked) decorations, and added the code to make sure the base/x is positive. If x is negative, the FPU will totally fail. You need to check the 'x' sign bit, plus consider odd/even bit of 'y', and apply the sign after it's finished! Lemme know what you think to any random reader. Looking for even better versions with x87 FPU code if possible. It compiles/works with Microsoft VC++ 2005 what I always stick with for various reasons.
Compatibility v. ANSI pow(x,y): Very good! Faster, predictable results, negative values are handled, just no error feedback for invalid input. But, if you know 'y' can always be an INT/LONG, do NOT use this version; I posted Agner Fog's version with some tweaks which avoids the very slow FSCALE, search my profile for it! His is the fastest x87/FPU way under those limited circumstances!
extern double __fastcall fs_Power(double x, double y);
// Main Source: The Svin
// pow(x,y) is equivalent to exp(y * ln(x))
// Version: 1.00
__declspec(naked) double __fastcall fs_Power(double x, double y) { __asm {
LEA EAX, [ESP+12] ;// Save 'y' index in EAX
FLD QWORD PTR [EAX] ;// Load 'y' (exponent) (works positive OR negative!)
FIST DWORD PTR [EAX] ;// Round 'y' back to INT form to test for odd/even bit
MOVZX EAX, WORD PTR [EAX-1] ;// Get x's left sign bit AND y's right odd/even bit!
FLD QWORD PTR [ESP+4] ;// Load 'x' (base) (make positive next!)
FABS ;// 'x' MUST be positive, BUT check sign/odd bits pre-exit!
AND AX, 0180h ;// AND off all bits except right 'y' odd bit AND left 'x' sign bit!
FYL2X ;// 'y' * log2 'x' - (ST(0) = ST(1) * log2 ST(0)), pop
FLD1 ;// Load 1.0f: 2 uses, mantissa extract, add 1.0 back post-F2XM1
FLD ST(1) ;// Duplicate current result
FPREM1 ;// Extract mantissa via partial ST0/ST1 remainder with 80387+ IEEE cmd
F2XM1 ;// Compute (2 ^ ST(0) - 1)
FADDP ST(1), ST ;// ADD 1.0f back! We want (2 ^ X), NOT (2 ^ X - 1)!
FSCALE ;// ST(0) = ST(0) * 2 ^ ST(1) (Scale by factor of 2)
FFREE ST(1) ;// Maintain FPU stack balance
;// Final task, make result negative if needed!
CMP AX, 0180h ;// Combo-test: Is 'y' odd bit AND 'x' sign bit set?
JNE EXIT_RETURN ;// If positive, exit; if not, add '-' sign!
FCHS ;// 'x' is negative, 'y' is ~odd, final result = negative! :)
EXIT_RETURN:
;// For __fastcall/__declspec(naked), gotta clean stack here (2 x 8-byte doubles)!
RET 16 ;// Return & pop 16 bytes off stack
}}
Alright, to wrap this experiment up, I ran a benchmark test using the RDTSC CPU time stamp/clocks counter instruction. I followed the advice of also setting the process to High priority with "SetPriorityClass(GetCurrentProcess(), HIGH_PRIORITY_CLASS);" and I closed out all other apps.
Results: Our retro x87 FPU Math function "fs_Power(x,y)" is 50-60% faster than the MSCRT2005 pow(x,y) version which uses a pretty long SSE branch of code labeled '_pow_pentium4:' if it detects a 64-bit >Pentium4+ CPU. So yaaaaay!! :-)
Notes: (1) The CRT pow() has a ~33 microsecond initialization branch it appears which shows us 46,000 in this test. It operates at a normal average after that of 1200 to 3000 cycles. Our hand-crafted x87 FPU beauty runs consistent, no init penalty on the first call!
(2) While CRT pow() lost every test, it DID win in ONE area: If you entered wild, huge, out-of-range/overflow values, it quickly returned an error. Since most apps don't need error checks for typical/normal use, it's irrelevant.
https://i.postimg.cc/QNbB7ZVz/FPUv-SSEMath-Power-Proc-Test.png
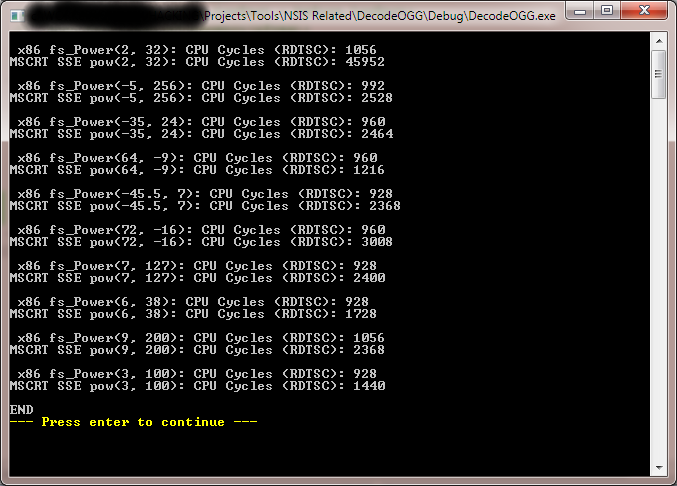{kind=link}
2nd Test (I had to run it again to copy/paste text after the image snap):
x86 fs_Power(2, 32): CPU Cycles (RDTSC): 1248
MSCRT SSE pow(2, 32): CPU Cycles (RDTSC): 50112
x86 fs_Power(-5, 256): CPU Cycles (RDTSC): 1120
MSCRT SSE pow(-5, 256): CPU Cycles (RDTSC): 2560
x86 fs_Power(-35, 24): CPU Cycles (RDTSC): 1120
MSCRT SSE pow(-35, 24): CPU Cycles (RDTSC): 2528
x86 fs_Power(64, -9): CPU Cycles (RDTSC): 1120
MSCRT SSE pow(64, -9): CPU Cycles (RDTSC): 1280
x86 fs_Power(-45.5, 7): CPU Cycles (RDTSC): 1312
MSCRT SSE pow(-45.5, 7): CPU Cycles (RDTSC): 1632
x86 fs_Power(72, -16): CPU Cycles (RDTSC): 1120
MSCRT SSE pow(72, -16): CPU Cycles (RDTSC): 1632
x86 fs_Power(7, 127): CPU Cycles (RDTSC): 1056
MSCRT SSE pow(7, 127): CPU Cycles (RDTSC): 2016
x86 fs_Power(6, 38): CPU Cycles (RDTSC): 1024
MSCRT SSE pow(6, 38): CPU Cycles (RDTSC): 2048
x86 fs_Power(9, 200): CPU Cycles (RDTSC): 1152
MSCRT SSE pow(9, 200): CPU Cycles (RDTSC): 7168
x86 fs_Power(3, 100): CPU Cycles (RDTSC): 1984
MSCRT SSE pow(3, 100): CPU Cycles (RDTSC): 2784
Any real world applications? YES! Pow(x,y) is used heavily to help encode/decode a CD's WAVE format to OGG and vice versa! When you're encoding a full 60 minutes of WAVE data, that's where the time-saving payoff would be significant! Many Math functions are used in OGG/libvorbis also like acos(), cos(), sin(), atan(), sqrt(), ldexp() (very important), etc. So fine-tuned versions like this, which don't bother/need error checks, can save lots of time!!
My experiment is the result of building an OGG decoder for the NSIS installer system which led to me replacing all the Math "C" library functions the algorithm needs with what you see above. Well, ALMOST, I need acos() in x86, but I STILL can't find anything for that...
Regards, and hope this is useful to anyone else that likes to tinker!
John Doe
- 303
- 1
- 8
-
Why not just use the [`fabs`](https://www.felixcloutier.com/x86/fabs) instruction? It's much faster (1 cycle latency on modern AMD and Intel) and doesn't cause a store-forwarding stall by writing half of a `double` right before you do a qword load of the whole thing. (You can still branch on the original value in memory at the end). Also, you don't need to save/restore EDX: it's call-clobbered in all the standard calling conventions. – Peter Cordes Jul 27 '19 at 04:10
-
Also you can avoid `fxch st1`. Use `fstp st(1)` to keep st0 = st0 while popping the stack. – Peter Cordes Jul 27 '19 at 04:12
-
`fprem` is slow. If you're just using that to get the integer and fractional parts, use `frndint` and subtract. (Hmm, according to https://agner.org/optimize/ `frndint` is also slow on Intel, but fast on Ryzen. Strange because SSE/AVX `roundpd` is fast) – Peter Cordes Jul 27 '19 at 04:16
-
(1) Yeah, regarding FRNDINT, I've been studying Agner Fog, he says it's very slow. (2) Honestly haven't timer-tested FABS after I've loaded a float versus INT commands to memory to AND off the sign bit. But given Agner, I think it *might* be faster, not 100%. ;) (3) I preserved EDX because I sorta prefer to know that all registers are preserved when I return from a call. I remember building DLLs in VC++, calling them in VB/VBA, but if EDI wasn't restored, you'd get a bad DLL calling convention. I inline ASM a lot more, try to use all registers, so peace of mind I don't break something. – John Doe Jul 27 '19 at 22:20
-
`fabs` is 1 uop with single-cycle latency. It's trivial to implement in an ALU, just clearing the sign bit. (Just like you or a compiler would do with `andps` for modern x86, using SSE1/SSE2 instead of legacy x87). re: calling conventions. Yes, EAX,ECX, and EDX are call-clobbered, the rest are call-preserved, in the standard 32-bit calling conventions. I would highly recommend *not* writing a lot of inline asm, compilers usually do a good job. Especially if you know why you can safely clobber EDX but not EDI, but just in general. Plus this syntax can only take inputs via memory, not regs – Peter Cordes Jul 27 '19 at 22:26
-
If you can assume that your number fits in an `int` or `int64_t`, you can use `fist` / `fild` to round to nearest integer (with the default rounding mode). Or SSE3 `fisttp` to truncate toward zero. – Peter Cordes Jul 27 '19 at 22:29
-
Additional defense of the INT method v. FABS: I need to know if 'x' is negative to restore the sign when the algorithm is finished. If I load the float, I'll have several commands to use to get the status to know if it's negative or not. I know there's less penalty dealing with x86 and the memory location a bit, so pretty good hunch this way was faster to both detect the sign bit, use DL as a flag for restoring the sign by the end, and AND'ing off the sign bit in memory in knowing how a float is stored. – John Doe Jul 27 '19 at 22:31
-
Yep, I use FLD / FISTP for rounding thanks to Agner, made macros for it when I'm in the mood to inline. I'm not sure I see how to work that here though because I didn't study the middle part of the algorithm. E.g.: #define ASM_FLOAT_TO_INT(FloatVar, IntVar) {__asm FLD FloatVar __asm FISTP IntVar} – John Doe Jul 27 '19 at 22:34
-
About "__fastcall" and "RET 16," I only learned that float numbers are always passed in the stack, and ECX/EDX won't get used here, but I want smaller code with __fastcall so the cleanup of stack is done here with "RET 16". I still code/maintain 32-bit apps, so dealing with 64-bit pure ASM modules where everything is passed in registers is not something I need to worry about. I think that's what you're referring to. There's no way to avoid passing floats in memory unless you declare (void) and use FLD pre-call, make it assume ST has top value, but that's "hackish..." I did that elsewhere. – John Doe Jul 27 '19 at 22:45
-
Like I said, use `fld` / `fabs` at the top of the function, then integer test+branch at the bottom like `test byte ptr [esp+7], 80h` / `jz non_negative`. There's no reason to introduce even normal store-forwarding latency by doing load/abs/store / reload, let alone a store-forwarding stall. If you conditionally jumped over a `fchs` at the top of the function, that would make some sense (and take 1 instruction out of the critical path assuming correct branch prediction). What I'm suggesting is fewer total instructions and smaller code-size, and the branch can resolve during slow FP stuff. – Peter Cordes Jul 27 '19 at 23:00
-
Oh, I gotcha. So just always do FABS, eliminate a bunch of that top code, and then at the bottom, grab the DWORD with bit 63 of the float to test if it was negative, use FCHS if true, etc... Hm, yeah, could be faster. I wish I could find my counter test scrap code. Thanks! – John Doe Jul 27 '19 at 23:06
-
re: calling conventions. You wrote this as a `naked` function so the compiler can't inline it into a caller. So yes of course you're stuck with the calling convention here. But if you had written it as a normal function containing an asm block, the compiler could inline it without needing a `ret` at all. But it would still need the inputs in memory because MSVC inline asm syntax doesn't have a way to tell the compiler where you want inputs / outputs the way GNU C inline asm does. – Peter Cordes Jul 27 '19 at 23:06
-
A `vectorcall` function could at least get doubles in XMM regs for SSE2 SIMD-integer shifts to extract/insert the exponent field as part of an efficient log2/exp2 implementation. – Peter Cordes Jul 27 '19 at 23:08
-
Yeah, I use naked if the code is long enough, and I lost trust with the __inline directive... Sometimes __inline causes me bugs, this was the last function where it did so to help decode a OGG audio file back to WAVE : extern float __fastcall fs_atan(float x) { __asm { FLD x ;// Load/Push input value FLD1 ;// Load 1.0 to compute full arctangent. FPATAN ;// Cmd: Partial arctangent [ atan(x) ] FSTP ST(1) ;// Pop1, Pop2 occurs on return }} – John Doe Jul 27 '19 at 23:09
-
1Yes, unconditional `fabs` at the top is what I'd do; no possibly-mispredicted branches until long after the FP value has been ready, so FP latency can hide the branch miss penalty. You don't need a dword load, just byte. `test [mem], imm8` / `jz` is smaller than `mov eax, [esp+4]` / `test eax,eax` / `jns`. Although doing the `mov eax, [esp+4]` before the slow microcoded FP instructions could be good for reducing branch mispredict detection latency for a `test/jns` at the end, in case the microcoded instructions tie up the front-end. – Peter Cordes Jul 27 '19 at 23:11
-
OK, I updated the code with the suggestions by @PeterCordes. It was vigorously tested with a OGG to WAVE decoder which heavily relies on the Math library as you can imagine. I've been building my own Math.h lib to avoid the bulk of the MSCRT and it's paid off with enough research. You can eliminate FWAIT after the very slow (according to Agner Fog) FSCALE, so 1 less line there. I'm inclined to leave it, but works w/o. About it, works with negative/positive which previous code samples don't provide. The CRT pow() has 50 SSE lines of code, so I'd bet this goes faster but test would be cool. – John Doe Jul 28 '19 at 02:29
-
You literally never need `fwait` ever on modern x86; anything with an integrated FPU. In fact I *think* you don't need `fwait` even on 286 and later. It's basically just a NOP so it only wastes front-end bandwidth. `ADD AL, AL` / `jnc` seems like an inefficient way to branch on the sign bit. Only Sandybridge-family can macro-fuse that into a single uop, vs. `test`/`jns` can macro-fuse even on Core2 and on AMD Bulldozer/Ryzen. And it still costs you a separate `mov` instruction to load+merge into the low byte of EAX. IDK why you're not using `movzx` to avoid a false dependency. – Peter Cordes Jul 28 '19 at 02:37
-
IDK why you'd assume that 50 SSE instructions would be faster than this. SSE doesn't have any super-slow micro-coded instructions; the slowest is `divsd` or `sqrtsd`. – Peter Cordes Jul 28 '19 at 02:43
-
If you think comparing source lines is useful even for a ballpark numbers, you *really* need to re-read Agner Fog's optimization guide about how out-of-order execution works!!! And his instruction tables to remind yourself just *how* slow they are compared to basic add/sub/mul operations. (And his microarch PDF (at least the Sandybridge and Ryzen sections). There's a reason that modern math libraries don't typically use the complex x87 instructions; they're usually not that faster than what you can do with software. – Peter Cordes Jul 28 '19 at 02:44
-
The add reg, reg, branch test for the sign bit comes from Agner Fog's doc "Optimizing subroutines in assembly language," page 156. It lets you test if the float is zero or negative since the sign bit shifts out to the CF. Quote: For example: ; Example 17.4a. Testing floating point value for zero fld dword ptr [ebx] ftst fnstsw ax and ah, 40h jnz IsZero can be replaced by mov eax, [ebx] add eax, eax jz IsZero where the ADD EAX,EAX shifts out the sign bit. – John Doe Jul 28 '19 at 02:51
-
Well, I'd love to run tests eventually, but I should think modern CPUs have improved the speed on these legacy x86 instructions to whatever extent. – John Doe Jul 28 '19 at 02:54
-
Agner's exact test for negative was this though: mov eax, [NumberToTest] cmp eax, 80000000H ja IsNegative So my version could go CMP AL, 80H; JA ToNegBranch. – John Doe Jul 28 '19 at 02:57
-
That's on page 162 in the current version (Apr 2018). The point of that is to shift out the sign bit and test *`ZF`*, not `CF`, because it's implementing `x == 0` not `x < 0`. (And with larger code-size, it could have done `test dword [ebx], 0x7FFFFFFF`). If you just want to test the sign bit, there are more efficient ways to do that, like what I suggested. `test [mem],imm8/jns` is at least as efficient as a `mov` load + `cmp / ja`. Anyway, if you are going to load and use `add`/`jnc` to test the sign bit, do a dword load to avoid partial-register stuff. And use `test eax,eax`/`jns` or jge – Peter Cordes Jul 28 '19 at 02:57
-
See also [Test whether a register is zero with CMP reg,0 vs OR reg,reg?](//stackoverflow.com/a/33724806). If you're going to load a value into a register, there's no point in using an immediate. And the only reason I suggested using a byte operand-size was so the immediate for `test` could be small. (Since you can't test a value against itself without first loading it into a register). But `cmp dword [esp+8], 0` could work, too – Peter Cordes Jul 28 '19 at 03:01
-
Yes, if you use JZ you're testing the ZF flag, but the code sets the CF for the purposes of using JNC, so it works fine/tested. The alternative is simply CMP AL, 80H. And true enough, (no idea you'd actually run to the page), but yeah, my copy of the doc is 2014. Didn't know he updated that PDF recently. My guess is ADD AL, AL might be faster for the job, then a subtract of 80H, but the advantage is the result's thrown away, while the add updates AL. I have to see the cycle counts, but that's why I preferred the ADD AL, AL. – John Doe Jul 28 '19 at 03:04
-
Anyway, re: speed of complex x87 instructions: your wishful thinking is not how real CPUs work. x87 is obsolete and CPU vendors are letting instructions like `fyl2x` get slower and slower vs. SSE1/SSE2, and on a clock-for-clock basis. e.g. Skylake `fyl2x` is 40-100 uops, with a latency of 103 cycles (surprisingly specific but no throughput number given). On Pentium II/III, it was 36-54 uops, and still 103 cycle latency (with a footnote: "not pipelined"). `fptan` is 140-160 cycle latency on Skylake, vs. 13-143 on Pentium II/II. Or 130 on Sandybridge. So yeah, they're getting worse. – Peter Cordes Jul 28 '19 at 03:08
-
Yes of course it *works* to do `add`/`jnc`. My entire point was that it's *less efficient* than most of the alternatives, especially on AMD CPUs and older Intel, where `test/jns` could macro-fuse but `add/jnc` can't. And if you're going to load into a register, use dword operand-size. The whole point of writing by hand in assembly language is to beat the compiler. If you're not doing that, you might as well write in C or C++ instead of spending the extra time on asm. (And yeah of course I looked it up to see WTF you were talking about; your first version of the comment was just a page ref) – Peter Cordes Jul 28 '19 at 03:09
-
I enjoy learning x86 and fine-tuning details. I already know "C" and since it's hobby freeware I am working on for this function, the extra time spent does not bother me. I don't know why you've become so aggravated and more certain that "ADD AL, AL" is the least efficient idea and that it "fails to beat the compiler, so I should go back to C/C++!" over that 1 idea. I think we're done here, thanks for your input so far. It's been informative. – John Doe Jul 28 '19 at 03:28
-
Conversely, I don't know why you spent so much time arguing against my suggestion of `test byte ptr [esp+11], 80h` / `jz non_negative` when that's obviously the smallest code-size, fewest instructions. I suggested it because (on Sandybridge-family and probably also AMD) it can macro-fuse + micro-fuse into a single test+branch uop. My impression that you maybe often aren't gaining much if anything vs. a compiler is based on more than just that, e.g. your idea that x87 instructions are still fast, and that you didn't notice the store-forwarding stall in your original integer fabs, etc. – Peter Cordes Jul 28 '19 at 03:46
-
But MSVC is usually the worst at optimizing of the 4 major x86 compilers (gcc/clang/ICC/MSVC), and using an old version of it just makes that worse. (I think I read something about improving their optimizer a lot around 2012.) So there's more room for improvement / more room to be faster than MSVC while still not being optimal. – Peter Cordes Jul 28 '19 at 03:49
-
What I found aggravating was that I explained why `test`/`jz` was faster in terms of microarchitectural reasons (macro-fusion on more CPUs), and then you kept arguing for something else and introducing a byte load into `al` instead of `eax`. `add` and `sub` have identical cost, and `add al,al` is not faster or smaller than `cmp al,80h`. But again if you want to test the top bit of a register, use `test al,al` / `jns`; that can macro-fuse on any CPU that does any kind of macro-fusion (Core2 and later, and AMD). – Peter Cordes Jul 28 '19 at 03:55
-
correction, I checked my notes and on Haswell/Skylake: `test dword [rdi], 0xff` / `je` is 2 uops total. It doesn't macro-fuse, only micro-fuses. So a separate `mov` load then `test eax,eax` / `jns` would be equal on current Intel. `test [mem], imm` / `jnz` might still be better on AMD, though. For current Intel to micro + macro-fuse, you need an instruction like `test [rdi], eax` (any addressing mode except RIP-relative which always blocks macro-fusion). But also no immediate. So `test byte ptr [esp+11], 0x80 / jnz` is only smaller than `mov eax,[esp+8]`/test/jns`, same speed on Intel. – Peter Cordes Jul 28 '19 at 04:20
-
I simply saw 2 methods that work from Agner's doc, "ADD AL, AL" and "CMP AL, 80h" - I prefer the ADD because it doesn't involve an immediate value, just deals with the register, so if I had to speculate between the two, it'd be faster. I can be persuaded otherwise if I see tests, so don't get angry from my speculation... I also recalled "SHL AL, 1", so the sign bit would shift right to the CF, yet another way. That seems a more complex op, but it also reports 1 clock cycle as the others. As for moving the byte from memory to AL first, that's habit, more intuitive to me. Thanks for your time. – John Doe Jul 28 '19 at 04:43
-
I don't get why you keep bringing up Agner's example 17.4a. That's testing for magnitude=0 which is the opposite of what you need. You need to test the sign bit and ignore the other bits. There's no reason to limit yourself to those 2 options based on seeing some barely-related example! re: tests: you can see in Agner's instruction tables that `add` and `cmp` have the same performance on their own, and no using an immediate is not slower. (And for AL specifically, doesn't take more code-size.) – Peter Cordes Jul 28 '19 at 04:48
-
The difference between `add` and `cmp` is macro-fusion on AMD CPUs, and Intel before SnB. Like I linked earlier, `test eax,eax`/`jge` or `jns` is best for comparing a register against zero (better than `cmp reg,0` or anything). If you're going to do a load into a register, then do a dword load instead of byte (to avoid any partial-reg stuff) and use `test same,same`. Macro-fusion is better than micro. The other good option is `test` with memory and immediate operands. You're correct that `shl` would be worse: it can't macro-fuse ever, and only runs on some of the possible ALU ports. – Peter Cordes Jul 28 '19 at 04:56
-
Oh, the SF/Sign Flag and using JNS, right, right... Yeah, that's more intuitive and what that flag is for! I wonder why Agner didn't go with TEST EAX, EAX / JNS if SF will be set after a basic/easy test. I use TEST for zero checks typically. He's why I stopped using FRNDINT assuring the reader it's slow on all processors even against the penalty of writing & reading back to memory from FPU his way. I figure he must know something about CMP EAX, 80000000h or the ADD way speedwise, that's why. I'm not limiting myself, I just figure 1 of his 2 ways are speed tweaks he learned & I just met you. – John Doe Jul 28 '19 at 05:39
-
Oh, you mean Agner's *Example 17.5*? That's a strange missed optimization. It has zero advantages vs. `test eax,eax` / `js negative`. He probably wrote that a long time ago and for whatever reason on that day he had a brain fart and forgot about `test` which can do the same thing with smaller code-size. `test/js` can macro-fuse on all CPUs that do any kind of macro-fusion, same as `cmp/ja`. But it doesn't need a 4-byte immediate. His point with that example is that you just need to look at the sign bit, not that you need to use `cmp` specifically. – Peter Cordes Jul 28 '19 at 05:48
-
Given the number in `st0` already, you could also use `fldz` and `fcomip`. Or `fxam` / `fstsw ax` and branch on the C1 bit. But those would probably both be worse than loading it again for an integer test like we've been talking about. – Peter Cordes Jul 28 '19 at 05:52
-
Oh, I just realized why he was using that `cmp eax, 80000000H` / `ja` (not `jae`). He wants to exclude `-0.0`. But you don't need to do that, it's fine if you `fchs` your result when the input was `-0.0` (because the output should also be `-0.0`). So you can treat the `80000000H` bit-pattern like a negative number. – Peter Cordes Jul 28 '19 at 05:58
-
Hang on, are you sure your `pow()` is even correct? `pow(-1, 2.0)` should be `+1` but your final branch always sets the output sign to the input sign. That's wrong for even powers. And I'm not sure `pow` is even defined for negative inputs and fractional powers, because `-1 ** 0.5` is sqrt(-1) = *i*, an imaginary number. – Peter Cordes Jul 28 '19 at 06:01
-
Also, you said something earlier about me "spending so much time" arguing against CMP, but I DID paste that Agner used that test for negative right after, I wrote: *"mov eax, [NumberToTest] cmp eax, 80000000H ja IsNegative. So my version could go CMP AL, 80H; JA ToNegBranch."*. But, my habit is avoiding immediate value tests so I used his ADD. I also felt dragging 1 byte from memory to AL is faster than 4 bytes to EAX and made that choice. You indicate the penalty for that with a test might offset/ruin that idea, perhaps. Anyway, you seem too combative, so I wanna end this... Good bye. – John Doe Jul 28 '19 at 06:07
-
Sorry I didn't notice sooner that Agner was using `ja` instead of `jae` with that and figure out what the point of using such a large immediate was. 1-byte loads are not faster than 4-byte aligned loads, especially not when it has to merge into the low byte of EAX instead of just replacing the whole EAX without keeping any bytes of the old value. (Requires a merging uop on modern Intel CPUs). And yes, avoiding immediates is generally good for code-size, so that's why you'd use `test eax,eax/jns`. Other than code-size there's usually no downside to immediates, though. – Peter Cordes Jul 28 '19 at 06:12
-
`AND AL, 1` is only efficient on Sandybridge-family. On AMD and earlier Intel, `test al, 1` can macro-fuse with `jz` but `and` can't. Also, you've created a dependency between those tests by reusing AL instead of EAX: [Why doesn't GCC use partial registers?](//stackoverflow.com/q/41573502) Anyway, yes checking for an even integer part works as long as your callers never pass `0.5`, only integer powers like `3` and `4`. Interesting that the 2 bits you need to test (sign of x, low bit of integer part of n) end up adjacent. Maybe one unaligned load of both bytes and AND / CMP to check for `10`? – Peter Cordes Jul 28 '19 at 07:18
-
Yeah, that update is like what I was suggesting. But did you test it with some test-cases? `TEST AX, 10000001b` is checking the high and low bit of AL: you only have 8 total bits. So you're not actually testing `y` being odd/even at all. I think you want `and eax, 110000000b` / `cmp eax, 110000000b` / `jne` to check that you have *both* an odd `int64_t(y)` (top bit) and negative `x` (the bit below that). Possibly I got this wrong in my head. You need to check that *both* bits are set (and/cmp), not that both are zero (test). – Peter Cordes Jul 28 '19 at 20:32
-
Also, use `movzx eax, word ptr[eax-1]` to avoid LCP stalls from decoding `and/cmp ax, imm16` or `test ax, imm16`. (Length-changing Prefix stalls, see Agner Fog's microarch pdf). The false dependency on the old value of EAX isn't a problem this time because you're using it for the load address so it already has to be ready. But merging into AX still costs an ALU uop vs. just zero-extending into EAX. – Peter Cordes Jul 28 '19 at 20:35
-