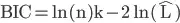As you all know, in k-mean clustering we can use Bayesian Information Criterion (BIC) for finding out what is the optimum number of clusters. The k that minimizes the BIC score is the optimal number of clusters according to the BIC scoring scheme.
The formulation for BIC is as follows:
BIC(C) = n*ln(RSS/n) + k*ln(n)
where n is the number of data points in the data set and k is the number of clusters. RSS is Residual sum of squares where we sum the distance of each data point from the centroid of its own cluster. Our data contains 3100 points where each point has two elements y=(x1, x2) (Each entry has two features).
My code in Matlab is as follows:
BIC=[];% Bayesian Information Criterion
n=3100; % number of datapoints
temp=1;
for k=1:50 % number of clusters
RSS=0; % residual sum of squares
[idx,C]=kmeans(y,k); % Matlab command for k-mean clustering
for i=1:3100
RSS=RSS+sqrt((y(i,1)-C(idx(i),1))^2+(y(i,2)-C(idx(i),2))^2);
end
BIC(temp)=n*log(RSS/n)+k*log(n);
temp=temp+1;
end
[p,l]=min(BIC);
plot(BIC)
But something is definitely wrong here in my code and I cannot say what! I mean if we let k from 1 to 100 then the k that minimizes BIC will be 100. If we let k from 1 to 1000 then the k that minimizes BIC will be 1000 and so on and so forth. But as far as I know there should be a specific k that minimizes BIC. I appreciate your help
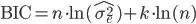 is only appropriate
is only appropriate