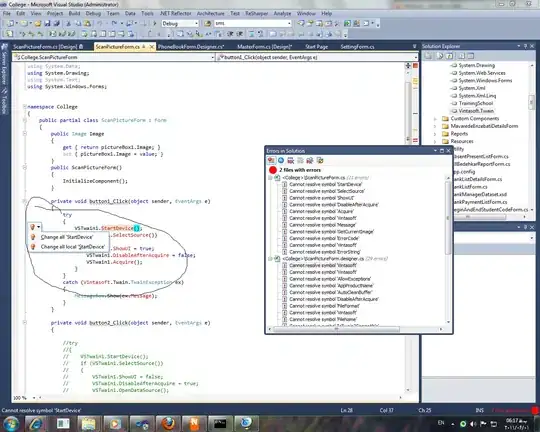
I have a dataset that looks like this:
A tibble: 935 x 17
wage hours iq kww educ exper tenure age married black south urban sibs brthord meduc
<int> <int> <int> <int> <int> <int> <int> <int> <fctr> <fctr> <fctr> <fctr> <int> <int> <int>
1 769 40 93 35 12 11 2 31 1 0 0 1 1 2 8
2 808 50 119 41 18 11 16 37 1 0 0 1 1 NA 14
3 825 40 108 46 14 11 9 33 1 0 0 1 1 2 14
4 650 40 96 32 12 13 7 32 1 0 0 1 4 3 12
5 562 40 74 27 11 14 5 34 1 0 0 1 10 6 6
6 1400 40 116 43 16 14 2 35 1 1 0 1 1 2 8
7 600 40 91 24 10 13 0 30 0 0 0 1 1 2 8
8 1081 40 114 50 18 8 14 38 1 0 0 1 2 3 8
9 1154 45 111 37 15 13 1 36 1 0 0 0 2 3 14
10 1000 40 95 44 12 16 16 36 1 0 0 1 1 1 12
...
What can I run to see the distribution of wage (the first column). Specifically, I want to see how many people have a wage of under $300.
What ggplot function can I run?