I want use PIL .save() method for export my PIL image list to pdf.
in the PIL document , saving part say:
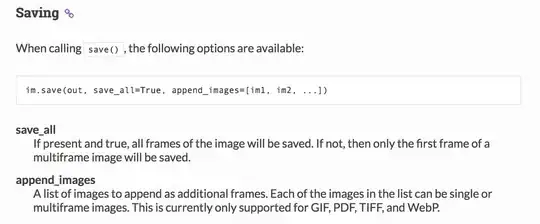 => we can use
=> we can use append_images option for pdf format.
and in pillow's github page , this issue say : Added append_images to PDF saving #2526
I wrote this code:
import PIL
im1 = PIL.Image.open("1.jpg").convert("RGB")
im2 = PIL.Image.open("2.jpg").convert("RGB")
im3 = PIL.Image.open("3.jpg").convert("RGB")
images = [im1,im2,im3]
images[0].save("out.pdf", save_all=True, append_images=images[1:])
but it doesn't work!
These errors raised:
Traceback (most recent call last):
File "sample.py", line 13, in <module>
gif.save("out.pdf", save_all=True, append_images=images)
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/PIL/Image.py", line 1928, in save
save_handler(self, fp, filename)
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/PIL/PdfImagePlugin.py", line 55, in _save_all
_save(im, fp, filename, save_all=True)
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/PIL/PdfImagePlugin.py", line 182, in _save
Image.SAVE["JPEG"](im, op, filename)
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/PIL/JpegImagePlugin.py", line 609, in _save
info = im.encoderinfo
AttributeError: 'Image' object has no attribute 'encoderinfo'