First of all, you need to decide whether you want to maintain a persistent connection to MySQL. The latter performs better, but need a little maintenance.
Default wait_timeout in MySQL is 8 hours. Whenever a connection is idle longer than wait_timeout it's closed. When MySQL server is restarted, it also closes all established connections. Thus if you use a persistent connection, you need to check before using a connection if it's alive (and if not, reconnect). If you use per request connection, you don't need to maintain the state of connection, because connection are always fresh.
Per request connection
A non-persistent database connection has evident overhead of opening connection, handshaking, and so on (for both database server and client) per each incoming HTTP request.
Here's a quote from Flask's official tutorial regarding database connections:
Creating and closing database connections all the time is very inefficient, so you will need to keep it around for longer. Because database connections encapsulate a transaction, you will need to make sure that only one request at a time uses the connection. An elegant way to do this is by utilizing the application context.
Note, however, that application context is initialised per request (which is kind of veiled by efficiency concerns and Flask's lingo). And thus, it's still very inefficient. However it should solve your issue. Here's stripped snippet of what it suggests as applied to pymysql:
import pymysql
from flask import Flask, g, request
app = Flask(__name__)
def connect_db():
return pymysql.connect(
user = 'guest', password = '', database = 'sakila',
autocommit = True, charset = 'utf8mb4',
cursorclass = pymysql.cursors.DictCursor)
def get_db():
'''Opens a new database connection per request.'''
if not hasattr(g, 'db'):
g.db = connect_db()
return g.db
@app.teardown_appcontext
def close_db(error):
'''Closes the database connection at the end of request.'''
if hasattr(g, 'db'):
g.db.close()
@app.route('/')
def hello_world():
city = request.args.get('city')
cursor = get_db().cursor()
cursor.execute('SELECT city_id FROM city WHERE city = %s', city)
row = cursor.fetchone()
if row:
return 'City "{}" is #{:d}'.format(city, row['city_id'])
else:
return 'City "{}" not found'.format(city)
Persistent connection
For a persistent connection database connection there are two major options. Either you have a pool of connections or map connections to worker processes. Because normally Flask WSGI applications are served by threaded servers with fixed number of threads (e.g. uWSGI), thread-mapping is easier and as efficient.
There's a package, DBUtils, which implements both, and PersistentDB for thread-mapped connections.
One important caveat in maintaining a persistent connection is transactions. The API for reconnection is ping. It's safe for auto-committing single-statements, but it can be disrupting in between a transaction (a little more details here). DBUtils takes care of this, and should only reconnect on dbapi.OperationalError and dbapi.InternalError (by default, controlled by failures to initialiser of PersistentDB) raised outside of a transaction.
Here's how the above snippet will look like with PersistentDB.
import pymysql
from flask import Flask, g, request
from DBUtils.PersistentDB import PersistentDB
app = Flask(__name__)
def connect_db():
return PersistentDB(
creator = pymysql, # the rest keyword arguments belong to pymysql
user = 'guest', password = '', database = 'sakila',
autocommit = True, charset = 'utf8mb4',
cursorclass = pymysql.cursors.DictCursor)
def get_db():
'''Opens a new database connection per app.'''
if not hasattr(app, 'db'):
app.db = connect_db()
return app.db.connection()
@app.route('/')
def hello_world():
city = request.args.get('city')
cursor = get_db().cursor()
cursor.execute('SELECT city_id FROM city WHERE city = %s', city)
row = cursor.fetchone()
if row:
return 'City "{}" is #{:d}'.format(city, row['city_id'])
else:
return 'City "{}" not found'.format(city)
Micro-benchmark
To give a little clue what performance implications are in numbers, here's micro-benchmark.
I ran:
uwsgi --http :5000 --wsgi-file app_persistent.py --callable app --master --processes 1 --threads 16uwsgi --http :5000 --wsgi-file app_per_req.py --callable app --master --processes 1 --threads 16
And load-tested them with concurrency 1, 4, 8, 16 via:
siege -b -t 15s -c 16 http://localhost:5000/?city=london
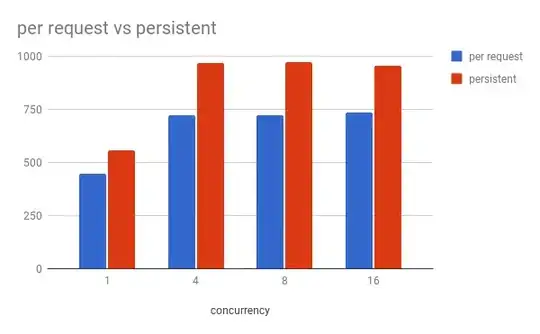
Observations (for my local configuration):
- A persistent connection is ~30% faster,
- On concurrency 4 and higher, uWSGI worker process peaks at over 100% of CPU utilisation (
pymysql has to parse MySQL protocol in pure Python, which is the bottleneck),
- On concurrency 16,
mysqld's CPU utilisation is ~55% for per-request and ~45% for persistent connection.