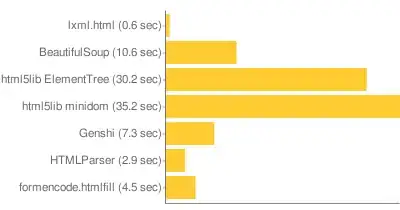
Currently I am having trouble typing this because, according to top, my processor is at 100% and my memory is at 85.7%, all being taken up by python.
Why? Because I had it go through a 250-meg file to remove markup. 250 megs, that's it! I've been manipulating these files in python with so many other modules and things; BeautifulSoup is the first code to give me any problems with something so small. How are nearly 4 gigs of RAM used to manipulate 250megs of html?
The one-liner that I found (on stackoverflow) and have been using was this:
''.join(BeautifulSoup(corpus).findAll(text=True))
Additionally, this seems to remove everything BUT markup, which is sort of the opposite of what I want to do. I'm sure that BeautifulSoup can do that, too, but the speed issue remains.
Is there anything that will do something similar (remove markup, leave text reliably) and NOT require a Cray to run?