i have a table that looks like this 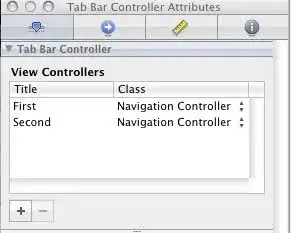
and i want to upload it to an array so the first colum would be city name and the first row will be the parameters. is it possible given different types? i need an array like this :
[[city name total 00-04 05-09]
[j 882806 110386 98268]
[a 221560 21982 19317]
[h 279591 21069 18200]]
when i use
csv = np.genfromtxt('populationData2016.csv',delimiter=",")
i get this
[[ nan nan nan ..., nan
nan nan]
[ nan 8.82806000e+05 1.10386000e+05 ..., 2.57210000e+04
1.77910000e+04 3.56080000e+04]