Hello guys I'm looking for a solution to my code where I try to convert a CSV file into an XLSX file and all my data gets reduced into one column separated by ;. (see the pics below)
Could you please help me to solve one of the two codes in order to make the data representation when converting equal to the csv file?? (see pictures)
The two following codes give the same result: (important, I am using Python 3.6 env on Jupyter Notebook):
import os
import glob
import csv
from xlsxwriter.workbook import Workbook
for csvfile in glob.glob(os.path.join('.', 'LOGS.CSV')):
workbook = Workbook(csvfile[:-4] + '.xlsx')
worksheet = workbook.add_worksheet()
with open(csvfile, 'r') as f:
reader = csv.reader((line.replace('\0','-') for line in f))
for r, row in enumerate (reader):
for c, col in enumerate(row):
worksheet.write(r, c, col)
workbook.close()
import os
import csv
import sys
from openpyxl import Workbook
data_initial = open("new.csv", "r")
sys.getdefaultencoding()
workbook = Workbook()
worksheet = workbook.worksheets[0]
with data_initial as f:
data = csv.reader((line.replace('\0','') for line in data_initial), delimiter=",")
for r, row in enumerate(data):
for c, col in enumerate(row):
for idx, val in enumerate(col.split('/')):
cell = worksheet.cell(row=r+1, column=c+1)
cell.value = val
workbook.save('output.xlsx')
This is my CSV file data organization:
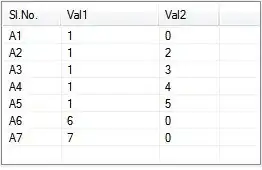
And this is what I get when I convert it into an XLSX:
Edit from comments
Okay, so I used @DeepSpace's program:
import pandas as pd
pd.read_csv('C:/Users/Pictures/LOGS.CSV')
.to_excel('C:/Users/Pictures/excel.xlsx')
and I am still getting this:
OKAY SOLUTION: The conversion is GREAT. But in my case the first column gets moved somehow. The Data num String is under nothing and the first column is its values... (see the pictures below)


import pandas as pd
filepath_in = "C:/Users/Pictures/LOGS.csv"
filepath_out = "C:/Users/Pictures/excel.xlsx"
pd.read_csv(filepath_in, delimiter=";").to_excel(filepath_out)