I am fairly new to R and am trying to find a rolling standard deviation over a period of several months (3, 6, 9) in integer groups. For instance, for a year of data and three groups, I would like to find the standard deviation for each group 1, 2, 3 for (Jan, Feb, Mar), (Feb, Mar, Apr), (Mar, Apr, May), etc.
In my dataframe df, I have column NUM: with the values to find standard deviation from, column NO: integers defining groups, and column date: which has daily dates. I also made column Yr_Mo, which is an integer corresponding to the year and month of a date. So for instance, all January dates in 2017 would have the value 1701 in the column Yr_Mo
For one month, I used aggregate: new <- aggregate( NUM ~ Yr_Mo + NO, df, sd )
This is pretty basic. However, it seems to be more complicated for groups of 3+ months. Because not all months are the same length and some months have missing dates, I cannot hardcode for certain time intervals. I've seen a lot of posts about similar questions to mine but these questions seem to ask in general about finding rolling std devs or else grouping but not both. I was thinking of using zoo functions such as rollapply, but again can't see how to consider both parts of my problem.
Thanks in advance for any help or pointers to documentation I might learn from!
NO date Yr_Mo NUM
1 2017-01-01 1701 3.4
1 2017-01-02 1701 5
1 2017-01-12 1701 4.2
1 2017-01-13 1701 1
1 2017-01-20 1701 6
1 2017-02-03 1702 3.9
1 2017-02-08 1702 5.5
1 2017-02-15 1702 8
1 2017-02-22 1702 1.1
1 2017-02-26 1702 4
1 2017-03-02 1703 1
1 2017-03-07 1703 7.5
1 2017-03-11 1703 2
1 2017-03-20 1703 3.1
1 2017-03-28 1703 2
1 2017-04-01 1704 2
1 2017-04-05 1704 3.5
1 2017-04-12 1704 1
1 2017-04-19 1704 4.1
1 2017-04-23 1704 5
1 2017-05-02 1705 1
1 2017-05-03 1705 4.5
1 2017-05-04 1705 2
1 2017-05-10 1705 6.1
1 2017-05-20 1705 7
2 2017-01-01 1701 3
2 2017-01-02 1701 53
2 2017-01-11 1701 2
2 2017-01-15 1701 4.1
2 2017-01-22 1701 1
2 2017-02-01 1702 8.9
2 2017-02-08 1702 1.5
2 2017-02-15 1702 3
2 2017-02-27 1702 7.2
2 2017-02-28 1702 4
2 2017-03-02 1703 1
2 2017-03-07 1703 5.2
2 2017-03-11 1703 2
2 2017-03-21 1703 1
2 2017-03-28 1703 2
2 2017-04-01 1704 2.4
2 2017-04-05 1704 3.5
2 2017-04-11 1704 1
2 2017-04-19 1704 4.1
2 2017-04-23 1704 3
2 2017-05-02 1705 1.2
2 2017-05-03 1705 4.5
2 2017-05-04 1705 2
2 2017-05-10 1705 6.1
2 2017-05-21 1705 9
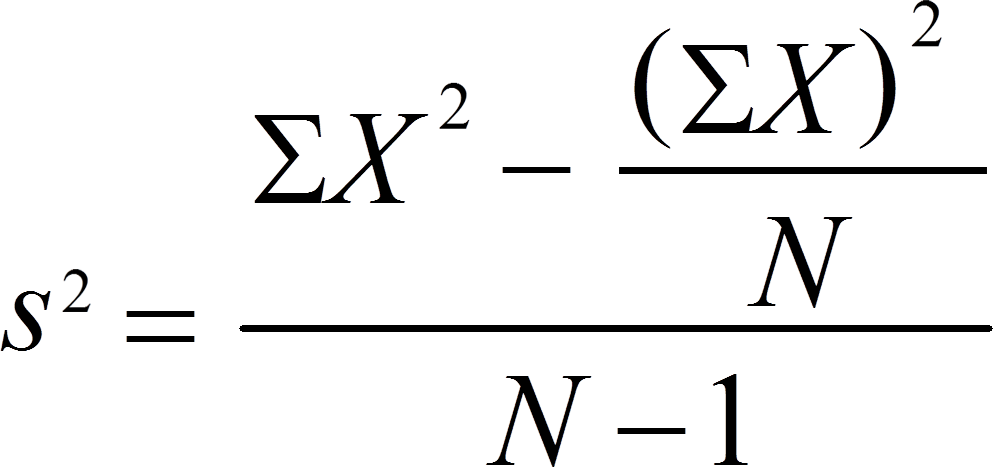{kind=link}