I've got a DataFrame that looks like this:
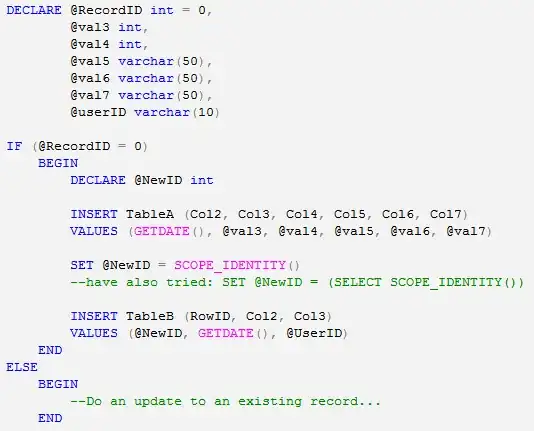
It has two columns, one of them being a "from" datetime and one of them being a "to" datetime. I would like to change this DataFrame such that it has a single column or index for the date (e.g. 2015-07-06 00:00:00 in datetime form) with the variables of the other columns (like deep) split proportionately into each of the days. How might one approach this problem? I've meddled with groupby tricks and I'm not sure how to proceed.