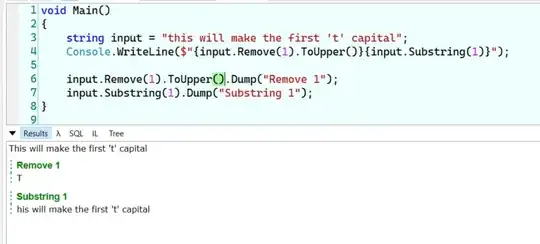
TL;DR
The opposite is actually the case. Higher precision calculations are less desired by frameworks like TensorFlow. This is due to slower training and larger models (more ram and disc space).
The long version
Neural networks actually benefit from using lower precision representations. This paper is a good introduction to the topic.
The key finding of our exploration is that deep neural networks can
be trained using low-precision fixed-point arithmetic, provided
that the stochastic rounding scheme is applied while operating on
fixed-point numbers.
They use 16 bit fixed point number rather than the much higher precession 32 bit floating point number (more information on their difference here).
The following image was taken from that paper. It shows the test error for different rounding schemes as well as the number of bits dedicated to the integer part of the fixed point representation. As you can see the solid red and blue lines (16 bit fixed) have a very similar error to the black line (32 bit float).
The main benefit/driver for going to a lower precision is computational cost and storage of weights. So the higher precision hardware would not give enough of an accuracy increase to out way the cost of slower computation.
Studies like this I believe are a large driver behind the specs for neural network specific processing hardware, such as Google's new TPU. Even though most GPUs don't support 16 bit floats yet Google is working to support it.
