I want to combine "text" column with first DataFrame where B value is closest <= A value. DataFrames length is not equal.
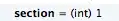
a = np.array(range(10, 35, 5))
b = np.array(range(0, 30, 5)) + 2
b_text = [random.choice(string.ascii_letters) for i in range(len(b))]
df1 = pd.DataFrame(a, columns=['A'])
df2 = pd.DataFrame(list(zip(b, b_text)), columns=['B', 'text'])