Well, there could be loads of reasons for that "very slight change". Scikit-Learn doesn't operate natively, it's built upon different libraries and it may be using loads of optimizers..etc!
Besides, your first graph is very close to linear!
Nevertheless, a big noticeable reasonable factor that contributed in those tiny changes is the Decomposition Method in Support Vector Machine.
The idea of decomposition methodology for classification tasks is to break down a complex classification task into several simpler and more manageable sub-tasks that are solvable by using existing induction methods, then joining their solutions together in order to solve the original problem.
This method is an iterative process and in each iteration only few variables are updated.
For more details about the mathematical approach, please refer to this paper, section 6.2 The Decomposition Method..
Moreover and specifically speaking, SVM implements two tricks called shrinking and caching for the decomposition method.
- The Shrinking idea is that an optimal solution
α of the SVM dual problem may contain some bounded elements (i.e., αi = 0 or C). These elements may have already been bounded in the middle of the decomposition iterations. To save the training time, the shrinking technique tries to identify and remove some bounded elements, so a smaller optimization problem is solved.
- The Caching idea is an effective technique for reducing the computational time of the decomposition method, so elements are calculated as needed. We can use available memory (called kernel cache) to store some recently used permutation of the matrix Qij. Then, some kernel elements may not need to be recalculate.
For more details about the mathematical approach, please refer to this paper, section 5 Shrinking and Caching.
Technical Proof:
I repeated your experiment (that's way I asked for your code to follow the same exact approach), with and without using the shrinking and caching optimization.
Using Shrinking and Caching
The default value of the parameter shrinking in sklearn SVC is set to True, keeping that as it is, produced the following output:

Plotting it gives:
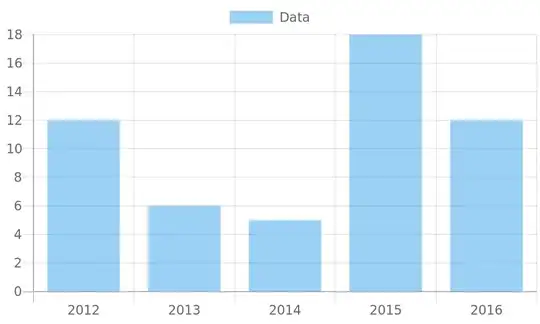
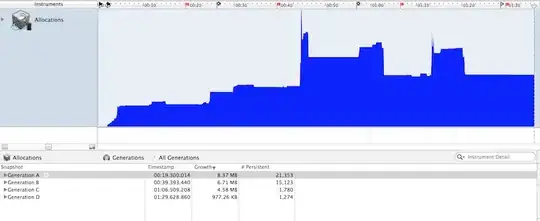
Note how at some point, the time drops noticeably reflecting the effect of shrinking and caching.
Without Using Shrinking and Caching
Using the same exact approach but this time, setting the parameter shrinking explicitly to False as follows:
clf = SVC(
C=best_params['C'],
kernel=str('linear'),
probability=False,
class_weight='balanced',
max_iter=max_iter,
random_state=2018,
verbose=True,
shrinking=False
)
Produced the following output:
Plotting it gives:
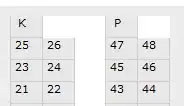
Note how unlike previous plot, there is no noticeable drop in time at some point, it's rather just a very tiny fluctuations along with the entire plot.
Comparing Pearson Correlations
In conclusion:
Without using the Shrinking and Caching (updated later with caching), the linearity improved, although it's not 100% linear, but if you take into account that Scikit-Learn internally uses libsvm library to handle all computations. And this library is wrapped using C and Cython, you would have a higher tolerance to your definition about 'Linear' of the relationship between maximum iterations and time. Also, here is a cool discussion about why algorithms may not give the exact same precise definite running time every time.
And that would be even clearer to you if you plot the interval times, so you can see clearly how the drops happen suddenly noticeably in more than one place.
While it keeps almost the same flow without using the optimization tricks.
Important Update
It turned out that the aforementioned reason for this issue (i.e. Shrinking and Caching) is correct, or more precisely, it's a very big factor of that phenomenon.
But the thing I missed is the following:
I was talking about Shrinking and Caching but I missed the later parameter for caching which is set by default to 200 MB.
Repeating the same simulations more than one time and setting the cache_size parameter to a very small number (because zero is not acceptable and throws an error) in addition to shrinking=False, resulted in an extremely-close-to linear pattern between max_iter and time:
clf = SVC(
C=best_params['C'],
kernel=str('linear'),
probability=False,
class_weight='balanced',
max_iter=max_iter,
random_state=2018,
verbose=False,
shrinking=False,
cache_size = 0.000000001
)
By the way, you don't need to set verbose=True, you can check if it reached the maximum iteration via the ConvergenceWarning, so you can redirect those warnings to a file and it'll be million times easier to follow, just add this code:
import warnings, sys
def customwarn(message, category, filename, lineno, file=None, line=None):
with open('warnings.txt', 'a') as the_file:
the_file.write(warnings.formatwarning(message, category, filename, lineno))
warnings.showwarning = customwarn
Also you don't need to re-generate the dataset after each iteration, so take it out the loop like this:
(X, y) = main(row_size, 40)
for it in m_iter:
....
....
Final Conclusion
Shrinking and Caching tricks coming from Decomposition Method in SVM play a big significant role in improving the execution time as the number of iterations increases. Besides, there are other small players that may be contributing in this matter such as internal usage of libsvm library to handle all computations which is wrapped using C and Cython.









