No, you probably have to do a bit of manual work to create an encoding for Python. The TTF file doesn't contain information about the Unicode mappings (it could but it's uncommon, and this one doesn't).
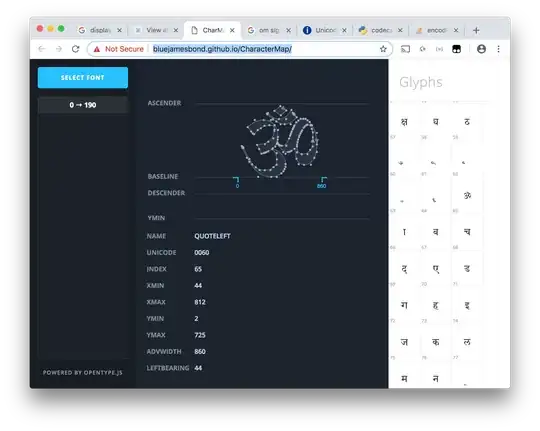
Looking at the font in http://bluejamesbond.github.io/CharacterMap/ I see many Devanagari glyphs but I don't know their names or what variations are common or permitted in drawing them so I probably can't easily find the same glyphs in Unicode for you. But I recognize the "om" glyph U+0950 on character code 65 (0x41) so I can contribute the first item in your encoding:
{
# ...
0x41: '\u0950',
# ...
}
Do this for all the other glyphs in the font and you have a mapping you can use in Python. The general guidance is in the documentation for the standard codecs module, but probably you want to find examples like Custom Python Charmap Codec too.