Based on suggestions by Jon Spring, I have tried to reformulate most of the code as follows.
library(tidyverse)
ka2 <- ka %>%
gather(Year, Export, -c(Economy, Partner)) %>%
group_by(Year) %>%
arrange(Year, -Export) %>%
top_n(10, wt = Export) %>%
ungroup()
ka2$Year <- gsub("X", "", ka2$Year)
ka2$Economy <- NULL
ka2 <- droplevels(ka2)
sapply(ka2, class)
ka2$Year <- as.integer(ka2$Year)
library(ggplot2)
library(scales)
ggplot(ka2, aes(x=reorder(Partner, -Export), y = Export/1000000, fill = Partner)) +
geom_bar(stat = "identity") +
scale_y_continuous(labels = comma) +
theme(axis.text.x = element_text(angle = 90, hjust = 1),
legend.position = "none") +
labs(title = "Kazhakhstan Exports to Largest Partners, 2000-2015",
y = "Bln USD", x = element_blank()) +
facet_wrap(~ Year, scales = 'free_x')
The data.frame generated in due course is as follows:
structure(list(Partner = c("Switzerland", "Italy", "Russia",
"China", "France", "Iran", "Netherlands", "Israel", "Azerbaijan",
"Spain", "Switzerland", "Italy", "Russia", "France", "China",
"Iran", "Netherlands", "USA", "Israel", "Canada", "Italy", "Switzerland",
"Russia", "China", "France", "Iran", "Netherlands", "UK", "Spain",
"Romania", "Italy", "Switzerland", "China", "Russia", "France",
"Netherlands", "Iran", "UK", "Ukraine", "Israel", "Italy", "Switzerland",
"China", "Russia", "France", "Netherlands", "Israel", "Iran",
"Ukraine", "Turkey", "Italy", "China", "Russia", "France", "Switzerland",
"Netherlands", "Canada", "Ukraine", "Iran", "UK"), Year = c(2004L,
2004L, 2004L, 2004L, 2004L, 2004L, 2004L, 2004L, 2004L, 2004L,
2005L, 2005L, 2005L, 2005L, 2005L, 2005L, 2005L, 2005L, 2005L,
2005L, 2006L, 2006L, 2006L, 2006L, 2006L, 2006L, 2006L, 2006L,
2006L, 2006L, 2007L, 2007L, 2007L, 2007L, 2007L, 2007L, 2007L,
2007L, 2007L, 2007L, 2008L, 2008L, 2008L, 2008L, 2008L, 2008L,
2008L, 2008L, 2008L, 2008L, 2009L, 2009L, 2009L, 2009L, 2009L,
2009L, 2009L, 2009L, 2009L, 2009L), Export = c(3760396L, 3108975L,
2836286L, 1966911L, 1468224L, 712011L, 464600L, 322423L, 287125L,
281365L, 5509511L, 4190531L, 2926578L, 2665146L, 2422507L, 886118L,
877836L, 666028L, 661641L, 528132L, 6891644L, 6721180L, 3730037L,
3592514L, 3346969L, 2077598L, 1704555L, 1143876L, 968365L, 747116L,
7774224L, 7475877L, 5635914L, 4658919L, 3982705L, 2464262L, 2451368L,
1133234L, 1113097L, 1058817L, 11920317L, 11281326L, 7676609L,
6227049L, 5388682L, 4638669L, 2226504L, 2039530L, 2003343L, 1903764L,
6686756L, 5888593L, 3546967L, 3381509L, 2668219L, 2222452L, 1385352L,
1289161L, 1279004L, 1235083L)), .Names = c("Partner", "Year",
"Export"), row.names = c(NA, -60L), class = c("tbl_df", "tbl",
"data.frame"))
And, the image I have got is as this.
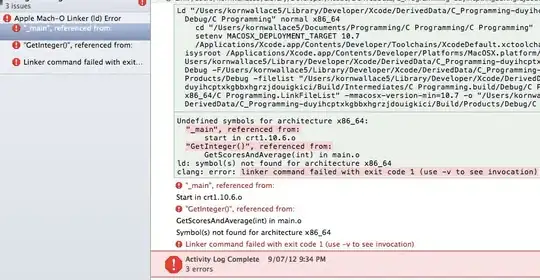
But, you can see even though each year displays the top 10 export destinations, they are not arranged in descending order. The data.frame was secured through arrangment of values in descending order, but display is not so. Hope this can be solved.
Based on the links and suggestions by Uwe, I have furthered my code as below.
ka2$ord <- rep(10:1,len=120)
ggplot(ka2, aes(x = -ord, y = Export/1000000, fill = Partner)) +
geom_bar(stat = "identity") +
scale_y_continuous(labels = comma) +
scale_x_discrete(labels = ka2[, setNames(as.character("Partner"), "ord")]) +
theme(axis.text.x = element_text(angle = 90, hjust = 1),
legend.position = "none") +
labs(title = "Kazhakhstan Exports to Largest Partners, 2004-2015",
y = "Bln USD", x = "Partner") +
facet_wrap(~ Year, scales = "free_x")
It gives me the result2 as follows.
The issue is that of axis.x labels.

{kind=link}