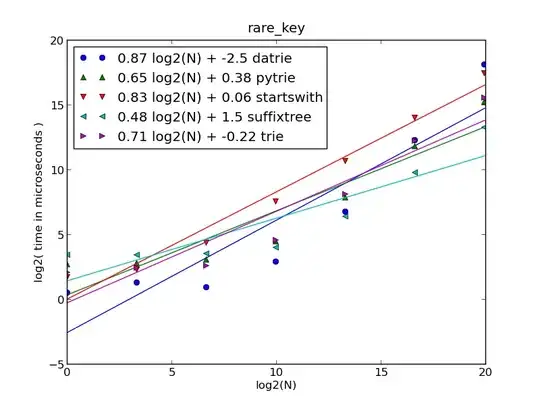
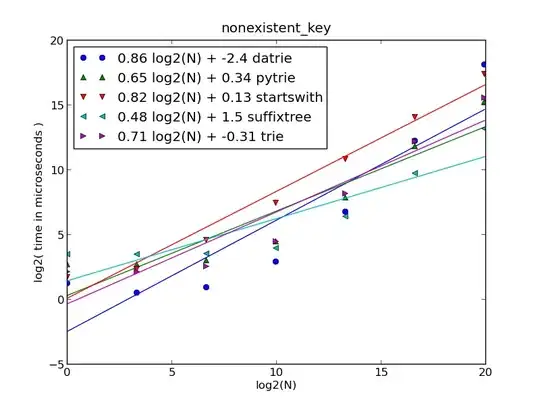
This example is good for small url lists but does not scale well.
def longest_prefix_match(search, urllist):
matches = [url for url in urllist if url.startswith(search)]
if matches:
return max(matches, key=len)
else:
raise Exception("Not found")
An implementation using the trie module.
import trie
def longest_prefix_match(prefix_trie, search):
# There may well be a more elegant way to do this without using
# "hidden" method _getnode.
try:
return list(node.value for node in prefix_trie._getnode(search).walk())
except KeyError:
return list()
url_list = [
'http://www.google.com/mail',
'http://www.google.com/document',
'http://www.facebook.com',
]
url_trie = trie.Trie()
for url in url_list:
url_trie[url] = url
searches = ("http", "http://www.go", "http://www.fa", "http://fail")
for search in searches:
print "'%s' ->" % search, longest_prefix_match(url_trie, search)
Result:
'http' -> ['http://www.facebook.com', 'http://www.google.com/document', 'http://www.google.com/mail']
'http://www.go' -> ['http://www.google.com/document', 'http://www.google.com/mail']
'http://www.fa' -> ['http://www.facebook.com']
'http://fail' -> []
or using PyTrie which gives the same result but the lists are ordered differently.
from pytrie import StringTrie
url_list = [
'http://www.google.com/mail',
'http://www.google.com/document',
'http://www.facebook.com',
]
url_trie = StringTrie()
for url in url_list:
url_trie[url] = url
searches = ("http", "http://www.go", "http://www.fa", "http://fail")
for search in searches:
print "'%s' ->" % search, url_trie.values(prefix=search)
I'm beginning to think a radix tree / patricia tree would be better from a memory usage point of view. This is what the a radix tree would look like:
Whereas the trie looks more like: