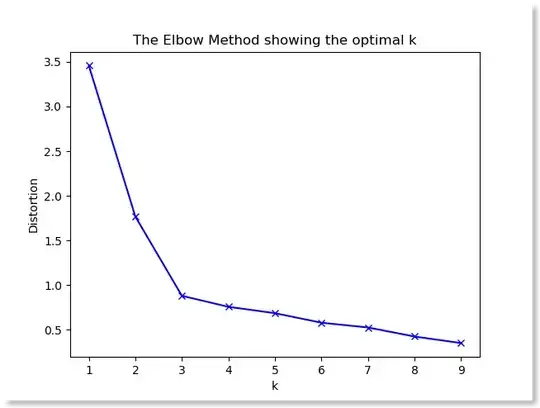
I want to cluster huge datasets but the bottleneck is the parameter tuning without visual checking.
Ex: K-means
I shouldn't try from 1 to N cluster if I have N samples, right? It's too brute force.
But what's range I should try? From 1 to N/4? or N/8? or the slope changing ratio?
In another words, how to determine the number of cluster without checking elbow point by my eyes?
Ex: DBSCAN
Follow here , choose the k-distance but is there a theory to help me decide the range of k?
Someone said using k-nn to help DBSCAN, but the k of k-nn is a complicated problem. How should I choose the range of k?
From above, I want to ask for help.
Anyone has the experience to cluster datasets and find a nearer (no need to very accurate) point to decide the parameter without visual checking?