I'm trying to read a file from the SD card and I've been told it's in unicode format. However, when I try to read the file I get the following:
This is the code I'm using to read the file:
InputStreamReader fw = new InputStreamReader(new FileInputStream(root.getAbsolutePath()+"/Drive/sdk/cmd.62.out"), "UTF-8");
char[] buf = new char[255];
fw.read(buf);
String readString = new String(buf);
Log.d("courierread",readString);
fw.close();
If I write that output to a file this is what I get when I open it in a hex editor:
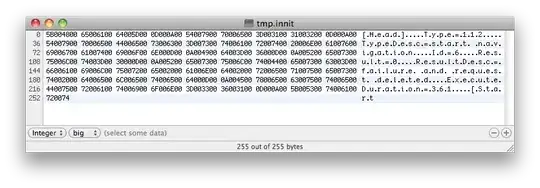
Any thoughts on what I need to do to read the file correctly?