I want to recognise the characters of NumberPlate. How to train the tesseract-ocr for respective number plate in ubuntu 16.04. Since i don't familiar with training. Please help me to create a 'traineddata' file for recognizing numberplate.
I have 1000 images of number plate.
Please look into it. Any help would be appreciate.
So I have tried the following commands
tesseract [langname].[fontname].[expN].[file-extension] [langname].[fontname].[expN] batch.nochop makebox
tesseract eng.arial.plate3655.png eng.arial.plate3655 batch.nochop makebox
But it gives error.
Tesseract Open Source OCR Engine v4.1.0-rc1-56-g7fbd with Leptonica
Error, cannot read input file eng.arial.plate3655.png: No such file or directory
Error during processing.
after that i have tried
tesseract plate4.png eng.arial.plate4 batch.nochop makebox
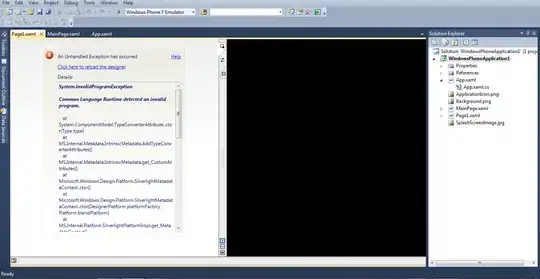
it works but in some plates. Now in Step 2. I am getting error.
Screenshot is attached.
Plate 4 image for training

Step 1 and Ste p2 display in terminal

File Generated after step 1 and step 2
Content of file generated after step 1 and step 2