I'm having some difficulty understanding the input-output flow of layers in stacked LSTM networks. Let's say i have created a stacked LSTM network like the one below:
# parameters
time_steps = 10
features = 2
input_shape = [time_steps, features]
batch_size = 32
# model
model = Sequential()
model.add(LSTM(64, input_shape=input_shape, return_sequences=True))
model.add(LSTM(32,input_shape=input_shape))
where our stacked-LSTM network consists of 2 LSTM layers with 64 and 32 hidden units respectively. In this scenario, we expect that at each time-step the 1st LSTM layer -LSTM(64)- will pass as input to the 2nd LSTM layer -LSTM(32)- a vector of size [batch_size, time-step, hidden_unit_length], which would represent the hidden state of the 1st LSTM layer at the current time-step. What confuses me is:
- Does the 2nd LSTM layer -LSTM(32)- receives as
X(t)(as input) the hidden state of the 1st layer -LSTM(64)- that has the size[batch_size, time-step, hidden_unit_length]and passes it through it's own hidden network - in this case consisting of 32 nodes-? - If the first is true, why the
input_shapeof the 1st -LSTM(64)- and 2nd -LSTM(32)- is the same, when the 2nd only processes the hidden state of the 1st layer? Shouldn't in our case haveinput_shapeset to be[32, 10, 64]?
I found the LSTM visualization below very helpful (found here) but it doesn't expand on stacked-lstm networks:
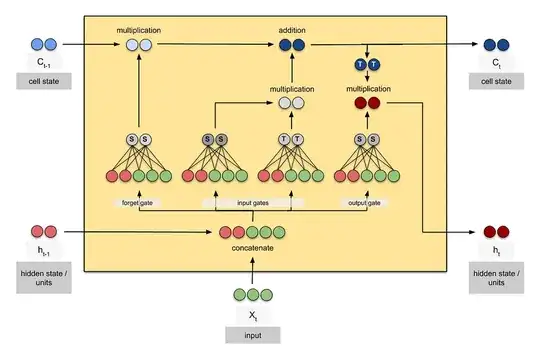
Any help would be highly appreciated. Thanks!

