I have following data shapes
X_Train.shape,Y_Train.shape
Out[52]: ((983, 19900), (983,))
X_Test.shape,Y_Test.shape
Out[53]: ((52, 19900), (52,))
I am running a simple binary classifier as Y_train and Y_test could be either 1 or 2
import keras
import tensorflow as tf
from keras import layers
from keras.layers import Input, Dense
from keras.models import Model,Sequential
import numpy as np
from keras.optimizers import Adam
myModel = keras.Sequential([
keras.layers.Dense(1000,activation=tf.nn.relu,input_shape=(19900,)),
keras.layers.Dense(64, activation=tf.nn.relu),
keras.layers.Dense(32, activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.softmax)
])
myModel.compile(optimizer='adam', loss='sparse_categorical_crossentropy',metrics=['accuracy'])
myModel.fit(X_Train, Y_Train, epochs=100,batch_size=1000)
test_loss,test_acc=myModel.evaluate(X_Test,Y_Test)
Output of the Code
Training Loss and Accuracy
Epoch 1/100
983/983 [==============================] - 1s 1ms/step - loss: nan - acc: 0.4608
Epoch 2/100
983/983 [==============================] - 0s 206us/step - loss: nan - acc: 0.4873
Epoch 3/100
983/983 [==============================] - 0s 200us/step - loss: nan - acc: 0.4883
Epoch 4/100
983/983 [==============================] - 0s 197us/step - loss: nan - acc: 0.4883
Epoch 5/100
983/983 [==============================] - 0s 194us/step - loss: nan - acc: 0.4873
Epoch 6/100
983/983 [==============================] - 0s 202us/step - loss: nan - acc: 0.4863
Epoch 7/100
983/983 [==============================] - 0s 198us/step - loss: nan - acc: 0.4863
Epoch 8/100
983/983 [==============================] - 0s 194us/step - loss: nan - acc: 0.4883
Epoch 9/100
983/983 [==============================] - 0s 196us/step - loss: nan - acc: 0.4873
Epoch 10/100
983/983 [==============================] - 0s 198us/step - loss: nan - acc: 0.4873
Epoch 11/100
983/983 [==============================] - 0s 200us/step - loss: nan - acc: 0.4893
Epoch 12/100
983/983 [==============================] - 0s 198us/step - loss: nan - acc: 0.4873
Epoch 13/100
983/983 [==============================] - 0s 194us/step - loss: nan - acc: 0.4873
Epoch 14/100
983/983 [==============================] - 0s 197us/step - loss: nan - acc: 0.4883
Epoch 97/100
983/983 [==============================] - 0s 196us/step - loss: nan - acc: 0.4893
Epoch 98/100
983/983 [==============================] - 0s 199us/step - loss: nan - acc: 0.4883
Epoch 99/100
983/983 [==============================] - 0s 193us/step - loss: nan - acc: 0.4883
Epoch 100/100
983/983 [==============================] - 0s 196us/step - loss: nan - acc: 0.4863
Testing Loss and Accuracy
test_loss,test_acc
Out[58]: (nan, 0.4615384661234342)
I also checked if there is any nan value in my data
np.isnan(X_Train).any()
Out[5]: False
np.isnan(Y_Train).any()
Out[6]: False
np.isnan(X_Test).any()
Out[7]: False
np.isnan(Y_Test).any()
Out[8]: False
My Question is why my training accuracy is not improving and why loss is nan also why without one-hot encoding the softmax in the output is working fine?
Note1: I apologize that my data is big so I cannot share it here but if there are some way to share it here then I am ready to do that.
Note2 There are lot of zero values in my training data
 .
.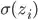 will be 1 for all values of
will be 1 for all values of 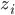 .
.