There is no option you can pass into Puppeteer to force PDF downloads. However, you can use chrome-devtools-protocol to add a content-disposition: attachment response header to force downloads.
A visual flow of what you need to do:
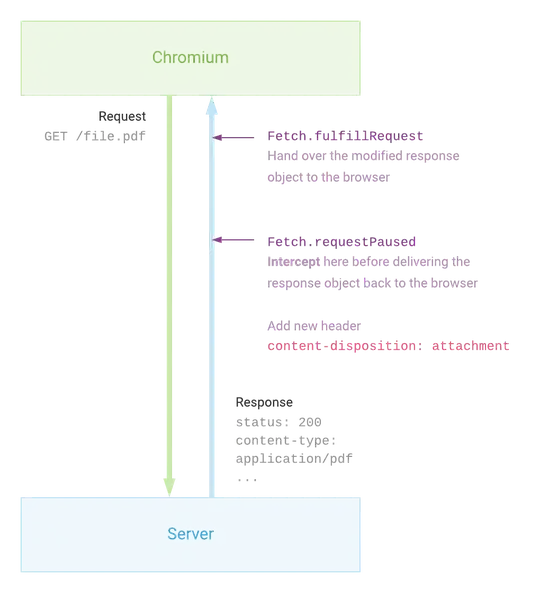
I'll include a full example code below. In the example below, PDF files and XML files will be downloaded in headful mode.
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: false,
defaultViewport: null,
});
const page = await browser.newPage();
const client = await page.target().createCDPSession();
await client.send('Fetch.enable', {
patterns: [
{
urlPattern: '*',
requestStage: 'Response',
},
],
});
await client.on('Fetch.requestPaused', async (reqEvent) => {
const { requestId } = reqEvent;
let responseHeaders = reqEvent.responseHeaders || [];
let contentType = '';
for (let elements of responseHeaders) {
if (elements.name.toLowerCase() === 'content-type') {
contentType = elements.value;
}
}
if (contentType.endsWith('pdf') || contentType.endsWith('xml')) {
responseHeaders.push({
name: 'content-disposition',
value: 'attachment',
});
const responseObj = await client.send('Fetch.getResponseBody', {
requestId,
});
await client.send('Fetch.fulfillRequest', {
requestId,
responseCode: 200,
responseHeaders,
body: responseObj.body,
});
} else {
await client.send('Fetch.continueRequest', { requestId });
}
});
await page.goto('https://pdf-xml-download-test.vercel.app/');
await page.waitFor(100000);
await client.send('Fetch.disable');
await browser.close();
})();
For a more detailed explanation, please refer to the Git repo I've setup with comments. It also includes an example code for playwright.
{kind=link}