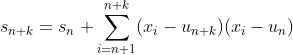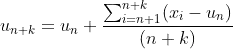I want to extend Welford's online algorithm to be able to be updated with multiple numbers (in batch) instead of just one at a time: https://en.wikipedia.org/wiki/Algorithms_for_calculating_variance
I tried to update the algorithm from the wiki page like this:
# my attempt.
def update1(existingAggregate, newValues):
(count, mean, M2) = existingAggregate
count += len(newValues)
delta = np.sum(np.subtract(newValues, [mean] * len(newValues)))
mean += delta / count
delta2 = np.sum(np.subtract(newValues, [mean] * len(newValues)))
M2 += delta * delta2
return (count, mean, M2)
# The original two functions from wikipedia.
def update(existingAggregate, newValue):
(count, mean, M2) = existingAggregate
count += 1
delta = newValue - mean
mean += delta / count
delta2 = newValue - mean
M2 += delta * delta2
def finalize(existingAggregate):
(count, mean, M2) = existingAggregate
(mean, variance, sampleVariance) = (mean, M2/count, M2/(count - 1))
if count < 2:
return float('nan')
else:
return (mean, variance, sampleVariance)
However, I must not understand it correctly, because the result is wrong:
# example x that might have led to an a = (2, 2.0, 2.0).
x = [1.0, 3.0]
mean = np.mean(x)
count = len(x)
m2 = np.sum(np.subtract(x, [mean] * count)**2)
a = (count, mean, m2)
print(a)
# new batch of values.
b = [5, 3]
Note that a = (2, 2.0, 2.0) means that we had 2 observations, and their mean was 2.0.
# update one at a time.
temp = update(a, newValues[0])
result_single = update(temp, newValues[1])
print(finalize(result_single))
# update with my faulty batch function.
result_batch = update1(a, newValues)
print(finalize(result_batch))
The correct output should be the one from applying the single number update twice:
(3.0, 2.0, 2.6666666666666665)
(3.0, 2.5, 3.3333333333333335)
What am I missing regarding the correct variance updates? Do I need to update the finalize function as well somehow?
The reason I need to do this, is because I am working with extremely large monthly files (with varying numbers of observations) and I need to get to yearly means and variances.