I'm trying to convert many PDF documents into text in R in order to use string parsing and regex to extract a set of codes from it. I am using ocr from the tesseract library and though it works on many of the pages, it does miss a lot of information that I need.
I identified the problem being inconsistent line breaks in the image/PDF. For example: 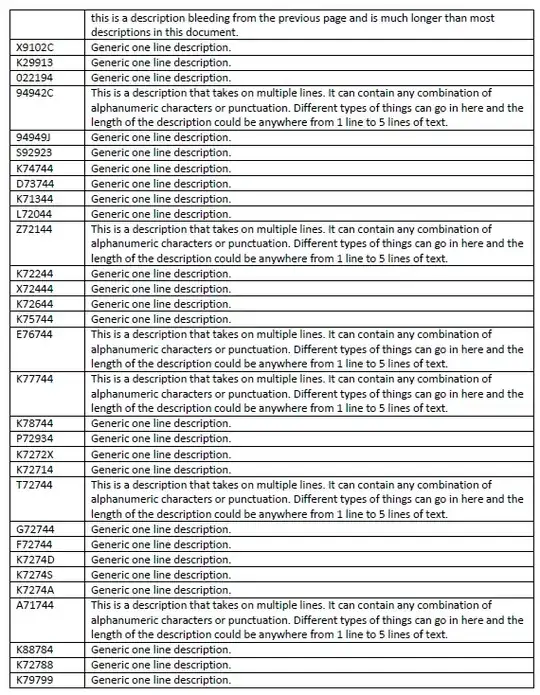
I am trying to get the codes from the left column. The only codes that I'm able to extract successfully are the ones where the description is longer than a single line.
I've experimented with various pre-processing techniques using magick but have come up short in most cases. The only instance where I was able to get the code set was cropping the right-hand side out of the image, but unfortunately this is not an efficient solution in my case.
file <- magick::image_read("44F245A2-5FEE-408F-A197-756436A5CAFD.png")
file %>%
magick::image_resize("2000x") %>%
magick::image_convert(type = 'Grayscale') %>%
tesseract::ocr() %>%
cat()
# or
# descriptions in this document.
# 94942C This is a description that takes on multiple lines. It can contain any combination of
# alphanumeric characters or punctuation. Different types of things can go in here and the
# | terpenes Steet gine see
# 272144 This is a description that takes on multiple lines. It can contain any combination of
# eee
# length of the description could be anywhere from 1 line to 5 lines of text.
# E76744 This is a description that takes on multiple lines. It can contain any combination of
# alphanumeric characters or punctuation. Different types of things can go in here and the
# [terpenes Steet gine see
# K77744 This is a description that takes on multiple lines. It can contain any combination of
# alphanumeric characters or punctuation. Different types of things can go in here and the
# | terrane een Steet gine seem
# 172744 This is a description that takes on multiple lines. It can contain any combination of
# Se
# length of the description could be anywhere from 1 line to 5 lines of text.
# A71744 This is a description that takes on multiple lines. It can contain any combination of
# alphanumeric characters or punctuation. Different types of things can go in here and the
# | teammates Steet gine see
Ideally I would like to be able to get all of the codes from the image in the above link. Any help would be awesome.