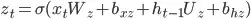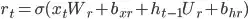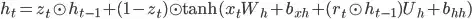Why the number of parameters of the GRU layer is 9600?
Shouldn't it be ((16+32)*32 + 32) * 3 * 2 = 9,408 ?
or, rearranging,
32*(16 + 32 + 1)*3*2 = 9408
model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=4500, output_dim=16, input_length=200),
tf.keras.layers.Bidirectional(tf.keras.layers.GRU(32)),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
model.summary()