First thing is this is maven dependency I used
<!-- https://mvnrepository.com/artifact/com.crealytics/spark-excel -->
<dependency>
<groupId>com.crealytics</groupId>
<artifactId>spark-excel_2.11</artifactId>
<version>0.12.0</version>
</dependency>
Questions : As far as I understand the future excel file is saved in the hdfs file system, right? I need to set the path of the future
excel file in .save() method, right? Also I don't understand what
format should be in dataAddress option?
what is data addess ?
from docs
Data Addresses: the location of
data to read or write can be specified with the dataAddress option.
Currently the following address styles are supported:
B3: Start cell of the data. Reading will return all rows below and all
columns to the right. Writing will start here and use as many columns
and rows as required. B3:F35: Cell range of data. Reading will return
only rows and columns in the specified range. Writing will start in
the first cell (B3 in this example) and use only the specified columns
and rows. If there are more rows or columns in the DataFrame to write,
they will be truncated. Make sure this is what you want. 'My
Sheet'!B3:F35: Same as above, but with a specific sheet.
MyTable[#All]: Table of data. Reading will return all rows and columns
in this table. Writing will only write within the current range of the
table. No growing of the table will be performed
so "My Sheet1'!B3:C35" means you are telling api that... My Sheet1 and B3:C35
column positions in the excel sheet..
The below is the complete listing through which I achieved desired..
package com.examples
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
object ExcelTest {
def main(args: Array[String]) {
import org.apache.spark.sql.functions._
Logger.getLogger("org").setLevel(Level.OFF)
val spark = SparkSession.builder.
master("local")
.appName(this.getClass.getName)
.getOrCreate()
import spark.implicits._
val df1 = Seq(
("2019-01-01 00:00:00", "7056589658"),
("2019-02-02 00:00:00", "7778965896")
).toDF("DATE_TIME", "PHONE_NUMBER")
df1.show()
val df2 = Seq(
("2019-01-01 01:00:00", "194.67.45.126"),
("2019-02-02 00:00:00", "102.85.62.100"),
("2019-03-03 03:00:00", "102.85.62.100")
).toDF("DATE_TIME", "IP")
df2.show()
df1.coalesce(1).write
.format("com.crealytics.spark.excel")
.option("dataAddress", "'My Sheet1'!B3:C35")
.option("useHeader", "true")
.option("dateFormat", "yy-mmm-d")
.option("timestampFormat", "mm-dd-yyyy hh:mm:ss")
.mode("append")
.save(".\\src\\main\\resources\\testexcel.xlsx")
df2.coalesce(1).write
.format("com.crealytics.spark.excel")
.option("dataAddress", "'My Sheet2'!B3:C35")
.option("useHeader", "true")
.option("dateFormat", "yy-mmm-d")
.option("timestampFormat", "mm-dd-yyyy hh:mm:ss")
.mode("append")
.save(".\\src\\main\\resources\\testexcel.xlsx")
}
}
Note : .coalesce(1) will create a single file not multiple part files...
Result : since i used local result will be saved in local if its yarn it will be in hdfs. if you want to use cloud storage like s3, its also possible with yarn as master. basically this is based on you requirements...

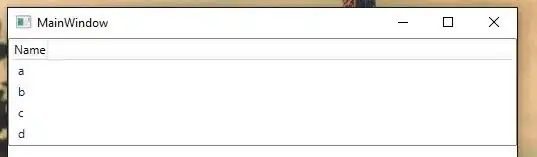
sheet 1 :
sheet 2 :
Also,
1) see my article How to do Simple reporting with Excel sheets using Apache Spark Scala ?
2) see my answer here.
Hope that helps!!


