tl;dr;
The page relies on javascript running in the browser to handle the table updates when selecting different dates. This process cannot occur when making a request with rvest.
I will give a fairly language agnostic description of what is going on and a potential solution. I will then show an implementation of that solution in Python. For R I was unsure on how to do dataframe operations within R to manage the 1-week change calculation. I may one day update this to include full R example too.
Some observations:
- Observation: If you disable javascript in the browser and reload the page you will see the table no longer updates.
- Conclusion: In order to get data for different dates javascript is running on the page (javascript does not run when you make a request with
rvest).
- Observation: If you monitor the web traffic via F12 dev tools, whilst making different date selections, no additional traffic is generated from the page due to date selections.
- Conclusion: All data required for updating the table is present upon page load and the javascript driving it is present.
The data source:
Based on these two observations a quick search of the source documents for the page soon reveals the javascript source and that the entire table is built dynamically.

The source link for this minified (compressed) js file is:
https://projects.fivethirtyeight.com/2017-nba-predictions/js/bundle.js?v=c1d7d294b039ddcc92b494602a5e337b
Table construction and population:
Looking further into this file we can see the instructions for dynamically constructing and populating the table:
Data population is handled by a series of functions which retrieve information from javascript objects within the file e.g.
And helper functions which, for example, round the elo and car-melo output:
Understanding how the data is stored:
The data we need is all within function 15; in an array of arrays:
So, an array of forecasts each containing an array of teams info.
If we were to zoom in on one date (i.e. a single item in the outer forecasts array) we would see:
If you look on the right hand side you can see each of the blocks associated with a different team for that particular date.
Retrieving the items and re-constructing a table with the columns of interest:
Sadly, the javascript notation in use here does not lend itself to easy parsing with a json library if one regex's out the array. In Python, at least, we have hjson which can handle unquoted keys (the var names) but that still ends an EOF error with trying to parse the info in this case (though it is possible I needed to alter my regex to terminate earlier - a musing for another time). But what we can do is the following:
- Make a request for that file and use its contents as a data source
- Grab the string associated with function 15
- Use regex to generate blocks by date (i.e. the array of items grouped by date that the javascript var
forecasts houses):

- Loop those blocks and extract lists of matches (by regex again) for
date, elo, car-melo and team. These lists can then be joined together into a dataframe for that date. The date field has to be repeated the length of one of the other columns (e.g. elo) as it only occurs once per block.
- Add in additional columns (or perform on the
elo and car-melo columns direct) for rounded elo and car-melo figures (you can replicate the original js implementation in image further up answer) or implement your own.
- Optionally add in a column so you have both abbreviated and long names for team. In my Python implementation I use a helper function
get_team_dict for this.
- You then need to generate the 1-week change values which means taking the final dataframe and performing a
GroupBy on TEAM and Sort By on Date desc.
- Perform a diff calculation on the groups between the current and next rows and generate an output column from the result.
- Potentially sort the grouped object on
Carmelo desc within the given date period (as page does).
- Do something with result e.g. write out to CSV.
Py implementation:
import requests, re
import pandas as pd
def get_data(n, response_text):
# n is function number within js e.g. 15: [function(s, _, n){}
# left slightly abstract so can examine various functions in particular js block
pattern = re.compile(f',{n}:(\[.+),{n+1}', re.DOTALL)
func_string = pattern.findall(response_text)[0]
return func_string
def get_team_dict(response_text):
p_teams = re.compile(r'abbrToFull:function\(s\){return{(.*?)}')
team_info = p_teams.findall(response_text)[0].replace('"','')
team_dict = dict(team.split(':') for team in team_info.split(','))
return team_dict
def get_column(block, pattern, length = 0): #p_block_elos, p_block_carmelos, p_block_teams, p_block_date
values = pattern.findall(block)
if length: values = values * length
return values
def get_df_from_processed_blocks(info_blocks, team_dict):
final = pd.DataFrame()
p_block_dates = re.compile(r'last_updated:"(.*?)T')
p_block_teams = re.compile(r'name:"(.*?)"')
p_block_elos = re.compile(r',elo:(.*?),')
p_block_carmelos = re.compile(r'carmelo:(.*?),')
for block in info_blocks:
if block == info_blocks[0]: block = block.split('forecasts:')[-1]
teams = get_column(block, p_block_teams)
teams_fullnames = [team_dict[team] for team in teams]
elos = get_column(block, p_block_elos)
rounded_elos = [round(float(elo)) for elo in elos] # generate rounded values similar to the js func
carmelos = get_column(block, p_block_carmelos)
rounded_carmelos = [round(float(carmelo)) for carmelo in carmelos]
dates = get_column(block, p_block_dates, len(elos)) # determine length of `elos` so can extend single date in block to match length for zipping lists for output
df = pd.DataFrame(list(zip(dates, teams, teams_fullnames, elos, rounded_elos, carmelos, rounded_carmelos)))
if final.empty:
final = df
else:
final = pd.concat([final, df], ignore_index = True)
return final
def get_date_sorted_df_with_change_column(final):
grouped_df = final.groupby(['TEAM (Abbr)'])
grouped_df = grouped_df.apply(lambda _df: _df.sort_values(by=['DATE'], ascending=False ))
grouped_df['1-WEEK CHANGE'] = pd.to_numeric(grouped_df['CARM-ELO'], errors='coerce').fillna(0).astype(int).diff(periods=-1)
# Any other desired changes to columns....
return grouped_df
def write_csv(final, file_name):
final.to_csv(f'C:/Users/User/Desktop/{file_name}.csv', sep=',', encoding='utf-8-sig',index = False, header = True)
def main():
response_text = requests.get('https://projects.fivethirtyeight.com/2017-nba-predictions/js/bundle.js?v=c1d7d294b039ddcc92b494602a5e337b').text
team_dict = get_team_dict(response_text)
p_info_blocks = re.compile(r'last_updated:".+?Z",teams.+?\]', re.DOTALL)
info_blocks = p_info_blocks.findall(get_data(15,response_text))
final = get_df_from_processed_blocks(info_blocks, team_dict)
headers = ['DATE', 'TEAM (Abbr)', 'TEAM (Full)', 'ELO', 'Rounded ELO', 'CARM-ELO', 'Rounded CARM-ELO']
final.columns = headers
grouped_df = get_date_sorted_df_with_change_column(final)
write_csv(grouped_df, 'scores')
if __name__ == "__main__":
main()
Understanding the regexes:
I would suggest pasting the regex pattern into an online regex engine and observing the description. Perhaps test against the source js file in browser or in editor. An example, the regex that generates the blocks, is saved here.
You should then be provided with some sort of explanation. DISCLAIMER: I am not a regex expert. Feel free to suggest improvements.
Comparing the output:
Here is an example comparison of the webpage and the output.
Webpage
Output:
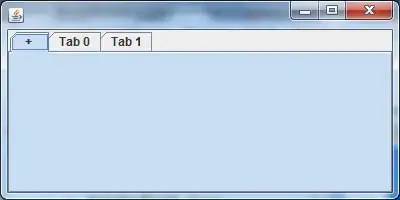
Reading:
- Regex








