@Nael Alsaleh, you can run K-Means the following way:
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
X=np.load('Mistery.npy')
wx = []
for i in range(1, 11):
kmeans = KMeans(n_clusters = i, random_state = 0)
kmeans.fit(X)
wx.append(kmeans.inertia_)
plt.plot(range(1, 11), wx)
plt.xlabel('Number of clusters')
plt.ylabel('Variance Explained')
plt.show()
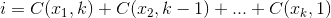
Note that X is a numpy array. This code will create the elbow curve, where you can select the perfect number of clusters, in this case, 5-6.
If you are working with numpy, you will have an array:
array([0.86992608, 0.11252552, 0.25573737, ..., 0.32652233, 0.14927118,
0.1662449 ])
You may also be working with a list,
[0.86992608, 0.11252552, 0.25573737, ..., 0.32652233, 0.14927118,
0.1662449 ]
that you will need to convert to array: np.array(X), or even a Pandas Dataframe:

You can check column types in a Pandas Dataframe by doing:
import pandas as pd
pd.DataFrame(X).dtypes
In numpy, x.dtype
After converting data to an array, run:
n=5
kmeans=KMeans(n_clusters=n, random_state=20).fit(X)
labels_of_clusters = kmeans.fit_predict(X)
This will get you the number of the cluster class that each example belongs.
array([1, 4, 0, 0, 4, 1, 4, 0, 2, 0, 0, 4, 3, 1, 4, 2, 2, 3, 0, 1, 1, 0,
4, 4, 2, 0, 3, 0, 3, 1, 1, 2, 1, 0, 2, 4, 0, 3, 2, 1, 1, 2, 2, 2,
2, 0, 0, 4, 1, 3, 1, 0, 1, 4, 1, 0, 0, 0, 2, 0, 1, 2, 2, 1, 2, 2,
0, 4, 4, 4, 4, 3, 1, 2, 1, 2, 2, 1, 1, 3, 4, 3, 3, 1, 0, 1, 2, 2,
1, 2, 3, 1, 3, 3, 4, 2, 2, 0, 2, 1, 3, 4, 2, 0, 2, 1, 3, 3, 3, 4,
3, 1, 4, 4, 4, 2, 0, 3, 2, 0, 1, 2, 2, 0, 3, 1, 1, 1, 4, 0, 2, 2,
0, 0, 1, 1, 0, 3, 0, 2, 2, 1, 2, 2, 4, 0, 1, 0, 3, 1, 4, 4, 0, 4,
1, 2, 0, 2, 4, 0, 1, 2, 3, 1, 1, 0, 3, 2, 4, 0, 1, 3, 1, 2, 4, 3,
1, 1, 2, 0, 0, 2, 3, 1, 3, 4, 1, 2, 2, 0, 2, 1, 4, 3, 1, 0, 3, 2,
4, 1, 4, 1, 4, 4, 0, 4, 4, 3, 1, 3, 4, 0, 4, 2, 1, 1, 3, 4, 0, 4,
4, 4, 4, 2, 4, 2, 3, 4, 3, 3, 1, 1, 4, 2, 3, 0, 2, 4])
To visualize:
from sklearn.datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples=200, centers=4,
cluster_std=0.60, random_state=0)
kmeans = KMeans(n_clusters=4, random_state=0).fit(X)
cc=kmeans.fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=cc, s=50, cmap='viridis')