I have a Pandas data frame (to illustrate the expected behavior) as follow:
df = pd.DataFrame({
'Id': ['001', '001', '002', '002'],
'Date': ['2013-01-07', '2013-01-14', '2013-01-07', '2013-01-14'],
'Purchase_Quantity': [12, 13, 10, 6],
'lead_time': [4, 2, 6, 4],
'Order_Quantity': [21, 34, 21, 13]
})
df['Date'] = pd.to_datetime(df['Date'])
df = df.groupby(['Id', 'Date']).agg({
'Purchase_Quantity': sum,
'lead_time': sum,
'Order_Quantity': sum})
Purchase_Quantity lead_time Order_Quantity
Id Date
001 2013-01-07 12 4 21
2013-01-14 13 2 34
002 2013-01-07 10 6 21
2013-01-14 6 4 13
Where lead_time is a duration in days.
I would like to add a column that keep track of the "quantity on hand" which is:
- Remaining quantity from previous weeks
- Plus ordered quantity that are finally available
- Minus purchased quantity of the current week
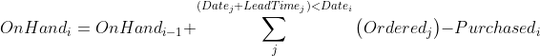
The expected result should be:
Purchase_Quantity lead_time Order_Quantity OH
Id Date
001 2013-01-07 12 4 21 0
2013-01-14 13 2 34 9
002 2013-01-07 10 6 21 0
2013-01-14 6 4 13 11