I'm trying to extract images from a pdf using PyPDF2, but when my code gets it, the image is very different from what it should actually look like, look at the example below:
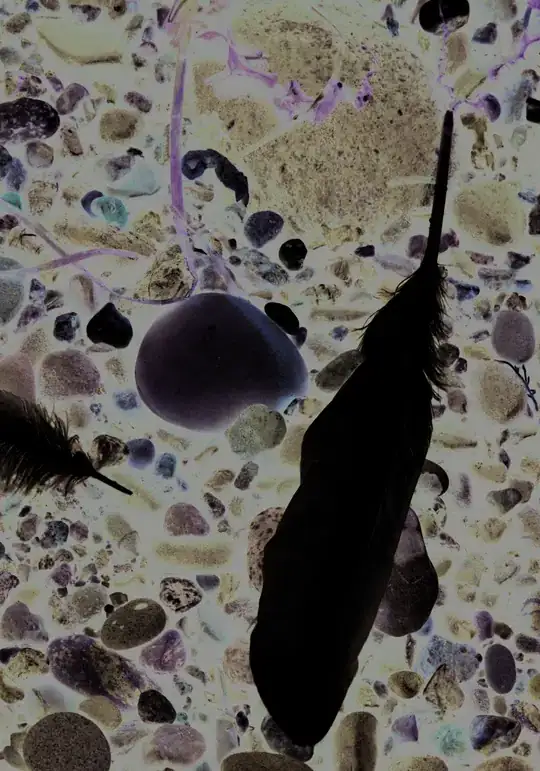 But this is how it should really look like:
But this is how it should really look like:

Here's the pdf I'm using:
https://www.hbp.com/resources/SAMPLE%20PDF.pdf
Here's my code:
pdf_filename = "SAMPLE.pdf"
pdf_file = open(pdf_filename, 'rb')
cond_scan_reader = PyPDF2.PdfFileReader(pdf_file)
page = cond_scan_reader.getPage(0)
xObject = page['/Resources']['/XObject'].getObject()
i = 0
for obj in xObject:
# print(xObject[obj])
if xObject[obj]['/Subtype'] == '/Image':
if xObject[obj]['/Filter'] == '/DCTDecode':
data = xObject[obj]._data
img = open("{}".format(i) + ".jpg", "wb")
img.write(data)
img.close()
i += 1
And since I need to keep the image in it's colour mode, I can't just convert it to RBG if it was CMYK because I need that information. Also, I'm trying to get dpi from images I get from a pdf, is that information always stored in the image? Thanks in advance