The following is a set of minor modifications to the initially provided code that will compute the estimate correctly.
I have marked modifications with comments prefixed by #### and numbered them with reference to the explanations that follow.
import random
#variable declaration
numberOfStreaks = 0
for experimentNumber in range(10000):
# Code that creates a list of 100 'heads' or 'tails' values.
CoinFlip = [] #### (1) create a new, empty list for this list of 100
for i in range(100):
CoinFlip.append(random.randint(0,1))
#does not matter if it is 0 or 1, H or T, peas or lentils. I am going to check if there is multiple 0 or 1 in a row
#### # (6) example / test
#### # if uncommented should be 100%
#### CoinFlip = [ 'H', 'H', 'H', 'H', 'H', 'H', 'T', 'T', 'T', 'T', 'T', 'T' ]
# Code that checks if there is a streak of 6 heads or tails in a row.
streak = 1 #### (2, 4) any flip is a streak of (at least) 1; reset for next check
for i in range(1, len(CoinFlip)): #### (3) start at the second flip, as we will look back 1
if CoinFlip[i] == CoinFlip[i-1]: #checks if current list item is the same as before
streak += 1
else:
streak = 1 #### (2) any flip is a streak of (at least) 1
if streak == 6:
numberOfStreaks += 1
break #### (5) we've found a streak in this CoinFlip list, skip to next experiment
#### if we don't, we get percentages above 100, e.g. the example / test above
#### this makes some sense, but is likely not what the book's author intends
print('Chance of streak: %s%%' % (numberOfStreaks / 100.0))
Explanation of these changes
The following is a brief explanation of these changes. Each is largely independent, fixing a different issue with the code.
- the clearing/creating of the CoinFlip list at the start of each experiment
- without this the new elements are added on to the list from the previous experiment
- the acknowledgement that any flip, even a single
'H' or 'T' (or 1 or 0), represents a streak of 1
- without this change the code actually requires six subsequent matches to the initial coin flip, for a total streak of seven (a slightly less intuitive alternative change would be to replace
if streak == 6: with if streak == 5:)
- starting the check from the second flip, using
range(1, len(CoinFlip)) (n.b. lists are zero-indexed)
- as the code looks back along the list, a
for loop with a range() starting with 0 would incorrectly compare index 0 to index -1 (the last element of the list)
- (moving the scope and) resetting the
streak counter before each check
- without this change an initial streak in an experiment could get added to a partial streak from a previous experiment (see Testing the code for a suggested demonstration)
- exiting the check once we have found a streak
This question in the book is somewhat poorly specified, and final part could be interpreted to mean any of "check if [at least?] a [single?] streak of [precisely?] six [or more?] is found". This solution interprets check as a boolean assessment (i.e. we only record that this list contained a streak or that it did not), and interprets a non-exclusively (i.e. we allow longer streaks or multiple streaks to count; as was true in the code provided in the question).
(Optional 6.) Testing the code
The commented out "example / test" allows you to switch out the normally randomly generated flips to the same known value in every experiment. In this case a fixed list that should calculate as 100%. If you disagree with interpretation of the task specification and disable the exit of the check described in (5.), you might expect the program to report 200% as there are two distinct streaks of six in every experiment. Disabling the break in combination with this input reports precisely that.
You should always use this type of technique (use known input, verify output) to convince yourself that code does or does not work as it claims or as you expect.
The fixed input CoinFlip = [ 'H', 'H', 'H', 'H', 'T', 'T', 'T' ] can be used to highlight the issue fixed by (4.). If reverted, the code would calculate the percentage of experiments (all with this input) containing a streak of six consecutive H or T as 50%. While (5.) fixes an independent issue, removing the break that was added further exacerbates the error and raises the calculated percentage to 99.99%. For this input, the calculated percentage containing a streak of six should be 0%.
You'll find the complete code, as provided here, produces estimates of around 80%. This might be surprising, but the author of the book hints that this might be the case:
A human will almost never write down a streak of six heads or six tails in a row, even though it is highly likely to happen in truly random coin flips.
- Al Sweigart, Coin Flip Streaks
You can also consider additional sources. WolframAlpha calculates that the chance of getting a "streak of 6 heads in 100 coin flips" is approximately 1 in 2. Here we are estimating the chance of getting a streak of 6 (or more) heads or a streak of six (or more) tails, which you can expect to be even more likely. As a simpler, independent example of this cumulative effect: consider that the chance of picking a heart from a normal pack of playing cards is 13 in 52, but picking a heart or a diamond would be 26 in 52.
Notes on the calculation
It may also help to understand that the author also takes a shortcut with calculating the percentage. This may confuses beginners looking at the final calculation.
Recall, a percentage is calculated:
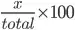
We know that total number of experiments to run will be 10000
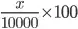
Therefore
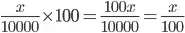
Postscript: I've taken the liberty of changing 100 to 100.0 in the final line. This allows the code to calculate the percentage correctly in Python 2. This is not required for Python 3, as specified in the question and book.