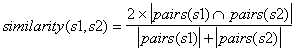This answer shows the solution using the fviz_cluster() function of the factoextra package, instead of the mock example included in my previous answer.
Starting off from the data frame posted by the OP that already includes the clusters found by hclust() and cutree():
structure(list(Latitude = c(-23.8, -23.8, -23.9, -23.9, -23.9,
-23.9, -23.9, -23.9, -23.9, -23.9, -23.9, -23.9, -23.9, -23.9,
-23.9, -23.9, -23.9, -23.9, -23.9), Longitude = c(-49.6, -49.6,
-49.6, -49.6, -49.6, -49.6, -49.6, -49.6, -49.6, -49.6, -49.7,
-49.7, -49.7, -49.7, -49.7, -49.6, -49.6, -49.6, -49.6), Waste = c(526,
350, 526, 469, 285, 175, 175, 350, 350, 175, 350, 175, 175, 364,
175, 175, 350, 45.5, 54.6), cluster = c(1L, 2L, 1L, 3L, 4L, 5L,
5L, 2L, 2L, 5L, 2L, 5L, 5L, 2L, 5L, 5L, 2L, 6L, 6L)), class = "data.frame",
row.names = c(NA, -19L))
we start by generating the plot of the clusters using fviz_cluster():
library(factoextra)
# Analysis variables (used when computing the clusters)
vars = c("Latitude", "Longitude", "Waste")
# Initial plot showing the clusters on the first 2 PCs
gg <- fviz_cluster(list(data = df, cluster = df$cluster), choose.vars=vars)
gg
which gives:
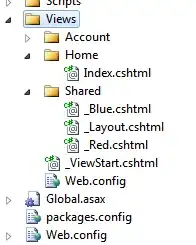
Note that this plot is different from the one shown by the OP. The reason is that the code used by the OP makes the cluster variable present in df to be included in the computation of the principal components on which the plot is based. The reason is that all variables in the input data frame are used to generate the plot.
(This conclusion was reached by looking at the source code of fviz_cluster() and running it in debug mode.)
Now we compute the Waste-weighted center of each cluster as well as the per-cluster average of Waste (needed below to add the centers to the plot):
(note that the code is now generalized to any number of clusters found)
# Number of clusters found
n_clusters = length( unique(df$cluster) )
# Waste-weighted cluster centers
center_mass <- matrix(nrow=n_clusters, ncol=2, dimnames=list(NULL, c("Latitude", "Longitude")))
for(i in 1:n_clusters) {
center_mass[i,] <- c(weighted.mean(subset(df,cluster==i)$Latitude,subset(df,cluster==i)$Waste),
weighted.mean(subset(df,cluster==i)$Longitude,subset(df,cluster==i)$Waste))
}
# We now compute the average Waste by cluster since,
# in order to add the centers to the fviz_cluster() plot
# we need the information for all three variables used
# in the clustering analysis and generation of the plot
center_mass_with_waste = cbind(center_mass, aggregate(Waste ~ cluster, mean, data=df))
head(center_mass_with_waste)
which gives:
Latitude Longitude cluster Waste
1 -23.85000 -49.60000 1 526.0000
2 -23.88344 -49.63377 2 352.3333
3 -23.90000 -49.60000 3 469.0000
4 -23.90000 -49.60000 4 285.0000
5 -23.90000 -49.64286 5 175.0000
6 -23.90000 -49.60000 6 50.0500
NOW the most interesting part starts: adding the weighted centers to the plot. Since the plot is done on the principal component axes, we need to compute the principal component coordinates for the centers.
This is achieved by running the principal component analysis (PCA) on the full data and applying the PCA axis rotation to the coordinates of the centers. There are at least two functions in the stats package of R that can be used to run PCA: prcomp() and princomp(). The preferred method is prcomp() (as it uses Singular Value Decomposition to perform the eigenanalysis and uses the usual N-1 as divisor for the variance as opposed to N which is used by princomp()). In addition prcomp() is the function used by fviz_cluster().
Therefore:
# We first scale the analysis data as we will need the center and scale information
# to properly center and scale the weighted centers for plotting
# Note that proper PCA is always done on centered and scaled data
# in order to accommodate different variable scales and make variables comparable.
# in addition, this is what is done inside fviz_cluster().
X <- scale( df[,vars] )
# We run PCA on the scaled data
summary( pca <- prcomp(X, center=FALSE, scale=FALSE) )
which gives:
Importance of components:
PC1 PC2 PC3
Standard deviation 1.2263 0.9509 0.7695
Proportion of Variance 0.5012 0.3014 0.1974
Cumulative Proportion 0.5012 0.8026 1.0000
Observe that the proportion of the explained variance by the first 2 PCs coincide with those shown in the initial plot of the clusters, namely: 50.1% and 30.1%, respectively.
We now center and scale the weighted centers, using the same center and scaling operation performed on the full data (this is needed for plotting):
# We center and scale the weighted centers
# (based on the information stored in the attributes of X)
center_mass_with_waste_scaled = scale(center_mass_with_waste[, vars],
center=attr(X, "scaled:center"),
scale=attr(X, "scaled:scale"))
# We compute the PC coordinates for the centers
center_mass_with_waste_pcs = predict(pca, center_mass_with_waste[,vars])
Fnally we add the Waste-weighted centers to the plot (as red filled points) and the Waste values as labels. Here we distinguish between number of analyzed variables (nvars) = 2 or > 2, since fviz_cluster() only performs PCA when nvars > 2, in the case nvars = 2 it just scales the variables.
# And finally we add the points to the plot (as red filled points)
# distinguishing two cases, because fviz_cluster() does different things
# in each case (i.e. no PCA when nvars = 2, just scaling)
if (length(vars) > 2) {
# fviz_cluster() performs PCA and plots the first 2 PCs
# => use PC coordinates for the centers
gg + geom_point(data=as.data.frame(center_mass_with_waste_pcs),
mapping=aes(x=PC1, y=PC2),
color="red", size=3) +
geom_text(data=as.data.frame(pca$x),
mapping=aes(x=PC1, y=PC2, label=df$Waste),
size=2, hjust=-0.5)
} else {
# fviz_cluster() does NOT perform PCA; it simply plots the standardized variables
# => use standardized coordinates for the centers
# Get the names of the analysis variables as expressions (used in aes() below)
vars_expr = parse(text=vars)
gg + geom_point(data=as.data.frame(center_mass_with_waste_scaled),
mapping=aes(x=eval(vars_expr[1]), y=eval(vars_expr[2])),
color="red", size=3) +
geom_text(data=as.data.frame(X),
mapping=aes(x=eval(vars_expr[1]), y=eval(vars_expr[2]), label=df$Waste),
size=2, hjust=-0.5)
}
which gives (when nvars = 3):
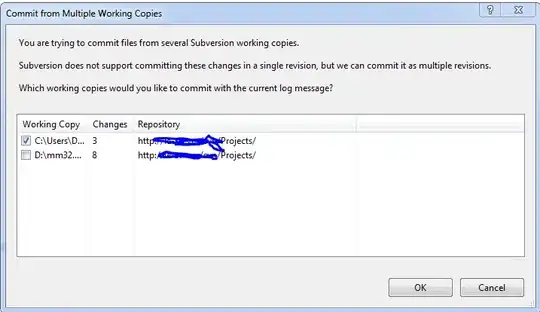
Note however that the red points essentially coincide with the original cluster centers computed by fiz_cluster() and this is because the Waste-weighted averages of Latitude and Longitude are almost the same as their respective non-weighted averages (furthermore, the only center that slightly differs between both calculation methods is the center for cluster 2 --as seen by comparing the weighted and unweighted averages per cluster (not done here)).