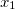TL:DR: if a mutex implementation uses acquire and release operations, could an implementation do compile-time reordering like would normally be allowed and overlap two critical sections that should be independent, from different locks? This would lead to a potential deadlock.
Assume a mutex is inmplement on std::atomic_flag:
struct mutex
{
void lock()
{
while (lock.test_and_set(std::memory_order_acquire))
{
yield_execution();
}
}
void unlock()
{
lock.clear(std::memory_order_release);
}
std::atomic_flag lock; // = ATOMIC_FLAG_INIT in pre-C++20
};
So far looks ok, regarding using single such mutex: std::memory_order_release is sychronized with std::memory_order_acquire.
The use of std::memory_order_acquire/std::memory_order_release here should not raise questions at the first sight.
They are similar to cppreference example https://en.cppreference.com/w/cpp/atomic/atomic_flag
Now there are two mutexes guarding different variables, and two threads accessing them in different order:
mutex m1;
data v1;
mutex m2;
data v2;
void threadA()
{
m1.lock();
v1.use();
m1.unlock();
m2.lock();
v2.use();
m2.unlock();
}
void threadB()
{
m2.lock();
v2.use();
m2.unlock();
m1.lock();
v1.use();
m1.unlock();
}
Release operations can be reordered after unrelated acquire operation (unrelated operation == a later operation on a different object), so the execution could be transformed as follows:
mutex m1;
data v1;
mutex m2;
data v2;
void threadA()
{
m1.lock();
v1.use();
m2.lock();
m1.unlock();
v2.use();
m2.unlock();
}
void threadB()
{
m2.lock();
v2.use();
m1.lock();
m2.unlock();
v1.use();
m1.unlock();
}
So it looks like there is a deadlock.
Questions:
- How Standard prevents from having such mutexes?
- What is the best way to have spin lock mutex not suffering from this issue?
- Is the unmodified mutex from the top of this post usable for some cases?
(Not a duplicate of C++11 memory_order_acquire and memory_order_release semantics?, though it is in the same area)