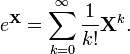BeatifulSoup is not the right tool for Youtube scraping_ - Youtube is generating a lot of content using JavaScript.
You can easily test it:
>>> import requests
>>> from bs4 import BeautifulSoup
>>> url = "https://www.youtube.com/results?search_query=python"
>>> response = requests.get(url)
>>> soup = BeautifulSoup(response.content,'html.parser')
>>> soup.find_all("a")
[<a href="//www.youtube.com/yt/about/en-GB/" slot="guide-links-primary" style="display: none;">About</a>, <a href="//www.youtube.com/yt/press/en-GB/" slot="guide-links-primary" style="display: none;">Press</a>, <a href="//www.youtube.com/yt/copyright/en-GB/" slot="guide-links-primary" style="display: none;">Copyright</a>, <a href="/t/contact_us" slot="guide-links-primary" style="display: none;">Contact us</a>, <a href="//www.youtube.com/yt/creators/en-GB/" slot="guide-links-primary" style="display: none;">Creators</a>, <a href="//www.youtube.com/yt/advertise/en-GB/" slot="guide-links-primary" style="display: none;">Advertise</a>, <a href="//www.youtube.com/yt/dev/en-GB/" slot="guide-links-primary" style="display: none;">Developers</a>, <a href="/t/terms" slot="guide-links-secondary" style="display: none;">Terms</a>, <a href="https://www.google.co.uk/intl/en-GB/policies/privacy/" slot="guide-links-secondary" style="display: none;">Privacy</a>, <a href="//www.youtube.com/yt/policyandsafety/en-GB/" slot="guide-links-secondary" style="display: none;">Policy and Safety</a>, <a href="/new" slot="guide-links-secondary" style="display: none;">Test new features</a>]
(pay attention there's that links you see on the screenshot are not present in the list)
You need to use another solution for that - Selenium might be a good choice. Please have at look at this thread for details Fetch all href link using selenium in python