Performance on real example:
Table Adres consists 320K rows of data. We need Adres.Id when we have Email (like in your example).
Database (and table Adres) collation is SQL_Latin1_General_CP1_CI_AS
For performance optimization, non-clustered index was created on column Email(Adres.Id column is included)
Queryies look like:
SELECT Adres.ID,Email FROM csc.Adres WHERE EMAIL ='23LMDLh6N@f8CyB7vPL.r4L'
SELECT Adres.ID,Email FROM csc.Adres WHERE EMAIL='23LMDLh6N@F8CyB7vPL.r4L' COLLATE Latin1_General_bin
1 row was returned for every query
results: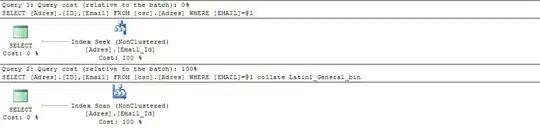
It seems that in second case query is not being identified as SARG by SQL Server. Why? Let us look at details.
In first case:
ScalarOperator ScalarString="CONVERT_IMPLICIT(nvarchar(4000),[@1],0)
And in second:
ScalarOperator ScalarString="CONVERT_IMPLICIT(nvarchar(80),[CSCENTRUMTest].[csc].[Adres].[Email],0)=CONVERT_IMPLICIT(nvarchar(4000),CONVERT(varchar(8000),[@1],0),0)">
So in second case Email is converted to required collation. This case is not SARG and index scan was performed.
If queries can not be identified as SARG (e.g. LIKE '%some email%)', plans are the same.
Assuming: if your query can be identified like SARG and you have appropriate index, no-collation is preferred (it is better to do collation conversation on client/service side).
You can find SARG information in different performance tuning books/articles.