I have the following table:
declare @table table (dates int , is_missing tinyint, group_id numeric(18))
insert into @table(dates,is_missing,group_id)
select 20110719,0,1
union all
select 20110720,0,1
union all
select 20110721,0,1
union all
select 20110722,1,1
union all
select 20110723,0,1
union all
select 20110724,0,1
union all
select 20110725,0,1
union all
select 20110726,1,1
union all
select 20110727,0,1
union all
select 20110728,1,1
union all
select 20110723,1,3
union all
select 20110724,0,3
union all
select 20110725,0,3
union all
select 20110726,1,3
union all
select 20110727,0,3
select * from @table
order by group_id, dates
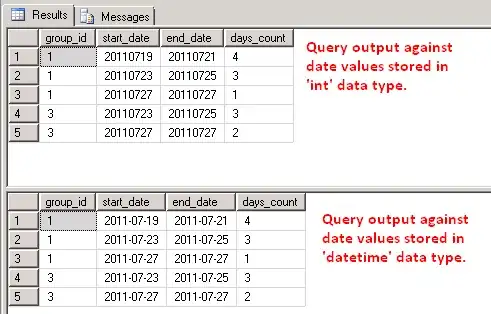
What I am trying to do is to return ranges of dates for each group which are identified by the missing day flag. To make this more clear the results of the query will have to look like this:
group_id start_date end_date days_count
1 20110719 20110721 3
1 20110723 20110725 3
1 20110727 20110727 1
3 20110724 20110725 2
3 20110727 20110727 1
The is_missing flag basicaly separates the ranges per group. It actually says that a date is missing and therefore all the other dates located between is_missing flags are the groups I am trying to find their start and end dates as well as their days numbers count.
Is there a simple way to do this?
Thanks a lot.