Others have already provided some excellent commentary, including analysis for the generated assembly code. I strongly recommend that you read them carefully. As they have pointed out this sort of question can't really be answered without some quantification, so let's and play with it a bit.
First, we're going to need a program. Our plan is this: we will generate strings whose lengths are powers of two, and try all functions in turn. We run through once to prime the cache and then separately time 4096 iterations using the highest-resolution available to us. Once we are done, we will calculate some basic statistics: min, max and the simple-moving average and dump it. We can then do some rudimentary analysis.
In addition to the two algorithms you've already shown, I will show a third option which doesn't involve the use of a counter at all, relying instead on a subtraction, and I'll mix things up by throwing in std::strlen, just to see what happens. It'll be an interesting throwdown.
Through the magic of television our little program is already written, so we compile it with gcc -std=c++11 -O3 speed.c and we get cranking producing some data. I've done two separate graphs, one for strings whose size is from 32 to 8192 bytes and another for strings whose size is from 16384 all the way to 1048576 bytes long. In the following graphs, the Y axis is the time consumed in nanoseconds and the X axis shows the length of the string in bytes.
Without further ado, let's look at performance for "small" strings from 32 to 8192 bytes:
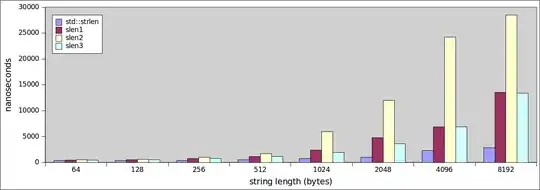
Now this is interesting. Not only is the std::strlen function outperforming everything across the board, it's doing it with gusto too since it's performance is a lot of more stable.
Will the situation change if we look at larger strings, from 16384 all the way to 1048576 bytes long?
Sort of. The difference is becoming even more pronounced. As our custom-written functions huff-and-puff, std::strlen continues to perform admirably.
An interesting observation to make is that you can't necessarily translate number of C++ instructions (or even, number of assembly instructions) to performance, since functions whose bodies consist of fewer instructions sometimes take longer to execute.
An even more interesting -- and important observation is to notice just how well the str::strlen function performs.
So what does all this get us?
First conclusion: don't reinvent the wheel. Use the standard functions available to you. Not only are they already written, but they are very very heavily optimized and will almost certainly outperform anything you can write unless you're Agner Fog.
Second conclusion: unless you have hard data from a profiler that a particular section of code or function is hot-spot in your application, don't bother optimizing code. Programmers are notoriously bad at detecting hot-spots by looking at high level function.
Third conclusion: prefer algorithmic optimizations in order to improve your code's performance. Put your mind to work and let the compiler shuffle bits around.
Your original question was: "why is function slen2 slower than slen1?" I could say that it isn't easy to answer without a lot more information, and even then it might be a lot longer and more involved than you care for. Instead what I'll say is this:
Who cares why? Why are you even bothering with this? Use std::strlen - which is better than anything that you can rig up - and move on to solving more important problems - because I'm sure that this isn't the biggest problem in your application.

