The final transformation does not remove the luminance, it creates two new values, x, y that together define the chromacity while Y contains the luminance. This is the key paragraph in your instructions link (just before the formulas you link):
The CIE XYZ color space was
deliberately designed so that the Y
parameter was a measure of the
brightness or luminance of a color.
The chromaticity of a color was then
specified by the two derived
parameters x and y, two of the three
normalized values which are functions
of all three tristimulus values X, Y,
and Z:
What this means is that if you have an image of a surface that has a single colour, but a part of the surface is in the shadow, then in the xyY space the x and y values should be the same (or very similar) for all pixels on the surface whether they are in the shadow or not.
The xyz values you get from the final transformation cannot be translated directly back to RGB as if they were XYZ values (note capitalization). So to answer your actual question: If you are using the xyz values as if they are XYZ values then there are no bugs in your code. Translation to RGB from that should not work using the formulas you linked.
Now if you want to actually remove the shadows from the entire image what you do is:
- scale your RGB values to be floating point valies in the [0-1] range by dividing each value by 255 (assuming 24-bit RGB). The conversion to floating point helps accuracy a lot!
- Convert the image to xyY
- Replace all Y values with one value, say 0.5, but experiment.
- Reverse the transformation, from xyY to XYZ:
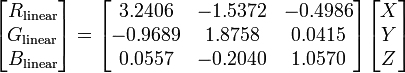
- Then rescale your RGB values on the [0..255] interval.
This should give you a very boring but shadowless version of your original image. Of course if your goal is detecting single colour regions you could also just do this on the xy values in the xyY image and use the regions you detect there on the original.
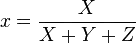
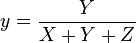
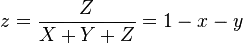
{kind=link}
{kind=link}