The '8' means it uses 8-bit blocks to represent a character. This does not mean that each character takes a fixed 8 bits. The number of blocks per character vary from 1 to 4 (though characters can be theorically upto 6 bytes long).
Try this simple test,
- Create a text file (in say Notepad++) with UTF8 without BOM encoding
- Read the text file (as you have done in your code) with
File.ReadAllBytes(). byte[] utf8 = File.ReadAllBytes(@"E:\SavedUTF8.txt");
- Check the number of bytes in taken by each character.
- Now try the same with a file encoded as ANSI
byte[] ansi = File.ReadAllBytes(@"E:\SavedANSI.txt");
- Compare the bytes per character for both encodings.
Note, File.ReadAllBytes() attempts to automatically detect the encoding of a file based on the presence of byte order marks. Encoding formats UTF-8 and UTF-32 (both big-endian and little-endian) can be detected.
Interesting results
SavedUTF8.txt contains character
a : Number of bytes in the byte array = 1 
© (UTF+00A9)(Alt+0169) : Number of bytes in the byte array = 2 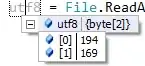
€: (UTF+E0A080)(Alt+14721152) Number of bytes in the byte array = 3 
ANSI encoding always takes 8 bits (i.e. in the above sample, the byte array will always be of size 1 irrespective of the character in the file). As pointed out by @tchrist, UTF16 takes 2 or 4 bytes per character (and not a fixed 2 bytes per character).
Encoding table (from here)
The following byte sequences are used to represent a character. The sequence to be used depends on the Unicode number of the character:
U-00000000 – U-0000007F: 0xxxxxxx
U-00000080 – U-000007FF: 110xxxxx 10xxxxxx
U-00000800 – U-0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx
U-00010000 – U-001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
U-00200000 – U-03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
U-04000000 – U-7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
The xxx bit positions are filled with the bits of the character code number in binary representation. The rightmost x bit is the least-significant bit. Only the shortest possible multibyte sequence which can represent the code number of the character can be used. Note that in multibyte sequences, the number of leading 1 bits in the first byte is identical to the number of bytes in the entire sequence.
Determining the size of character
The first byte of a multibyte sequence that represents a non-ASCII character is always in the range 0xC0 to 0xFD and it indicates how many bytes follow for this character.
This means that the leading bits for a 2 byte character (110) are different than the leading bits of a 3 byte character (1110). These leading bits can be used to uniquely identify the number of bytes a character takes.
More information