While trying to optimize a code, I'm a bit puzzled by differences in profiles produced by kcachegrdind and gprof. Specifically, if I use gprof (compiling with the -pg switch, etc), I have this:
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls ms/call ms/call name
89.62 3.71 3.71 204626 0.02 0.02 objR<true>::R_impl(std::vector<coords_t, std::allocator<coords_t> > const&, std::vector<unsigned long, std::allocator<unsigned long> > const&) const
5.56 3.94 0.23 18018180 0.00 0.00 W2(coords_t const&, coords_t const&)
3.87 4.10 0.16 200202 0.00 0.00 build_matrix(std::vector<coords_t, std::allocator<coords_t> > const&)
0.24 4.11 0.01 400406 0.00 0.00 std::vector<double, std::allocator<double> >::vector(std::vector<double, std::allocator<double> > const&)
0.24 4.12 0.01 100000 0.00 0.00 Wrat(std::vector<coords_t, std::allocator<coords_t> > const&, std::vector<coords_t, std::allocator<coords_t> > const&)
0.24 4.13 0.01 9 1.11 1.11 std::vector<short, std::allocator<short> >* std::__uninitialized_copy_a<__gnu_cxx::__normal_iterator<std::vector<short, std::alloca
Which seems to suggest that I need not bother looking anywhere but ::R_impl(...)
At the same time, if I compile without the -pg switch and run valgrind --tool=callgrind ./a.out instead, I have something rather different: here's a screenshot of the kcachegrind output
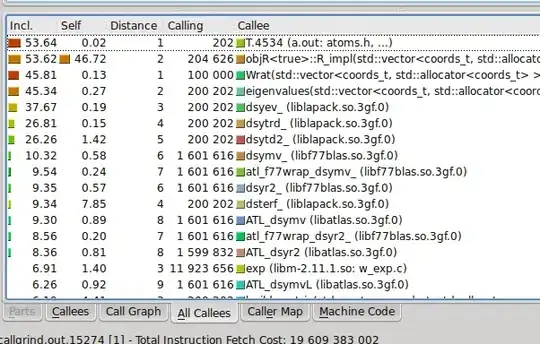
If I interpret this correctly, it seems to suggest that ::R_impl(...) only takes about 50% of time, while the other half is spent in linear algebra (Wrat(...), eigenvalues and the underlying lapack calls ) which was way down below in the gprof profile.
I understand that gprof and cachegrind use different techniques, and I'd not bother if their results were somewhat different. But here, it looks very different, and I'm at loss as to how to interpret those. Any ideas or suggestions?