NOTE: If you experience this issue as well, please upvote it on Apache JIRA:
I have come to an astonishing conclusion that this:
Element e = (Element) document.getElementsByTagName("SomeElementName").item(0);
String result = ((Element) e).getTextContent();
Seems to be an incredible 100x faster than this:
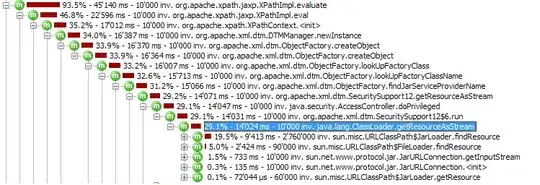
// Accounts for 30%, can be cached
XPathFactory factory = XPathFactory.newInstance();
// Negligible
XPath xpath = factory.newXPath();
// Negligible
XPathExpression expression = xpath.compile("//SomeElementName");
// Accounts for 70%
String result = (String) expression.evaluate(document, XPathConstants.STRING);
I'm using the JVM's default implementation of JAXP:
org.apache.xpath.jaxp.XPathFactoryImpl
org.apache.xpath.jaxp.XPathImpl
I'm really confused, because it's easy to see how JAXP could optimise the above XPath query to actually execute a simple getElementsByTagName() instead. But it doesn't seem to do that. This problem is limited to around 5-6 frequently used XPath calls, that are abstracted and hidden by an API. Those queries involve simple paths (e.g. /a/b/c, no variables, conditions) against an always available DOM Document only. So, if an optimisation can be done, it will be quite easy to achieve.
My question: Is XPath's slowness an accepted fact, or am I overlooking something? Is there a better (faster) implementation? Or should I just avoid XPath altogether, for simple queries?