The solution in here works just fine for me. But I would like to add some adjustments because the code will be slightly different for your data. According to the solution, we will use 3 geom objects that represent the elevation, FlowA, and FlowB. We will also make the secondary axis for FlowA and FlowB.
ggplot(FakeData, aes(x = Date))+
geom_line(aes(y = Elevation)) +
geom_col(aes(y = FlowA), fill="blue") +
geom_col(aes(y = FlowB), fill='red')+
scale_y_log10(sec.axis = sec_axis(~ .*1, labels = scales::number_format(scale=1/10),name="Flow"))
In the code above, I will show the elevation as a line plot and flows as a bar plot. Why did I use the logarithmic scale here? Because the distance of the elevation's value range(between 806.8 until 807.8) and the flows' value range is very far. If you proceed with a regular y-axis (scale_y_continuous()), you will have this plot below:
 See that the plot is not so meaningful. You can't see clearly how the flows change over time. Here's what it looks in logarithmic scale:
See that the plot is not so meaningful. You can't see clearly how the flows change over time. Here's what it looks in logarithmic scale:
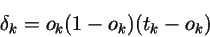 I use the logarithmic scale for the left y-axis and regular scale on the right y-axis. Now we can see clearly the changes in the flows over time. The Elevation will definitely be a straight line because you set it to be a random uniform distribution.
I use the logarithmic scale for the left y-axis and regular scale on the right y-axis. Now we can see clearly the changes in the flows over time. The Elevation will definitely be a straight line because you set it to be a random uniform distribution.
However, personally, I don't suggest you use a double y-axis because it confuses the plot user. I suggest you split the plot into two different plots.


