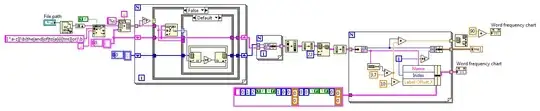
I have a JSON file
response ={
"classifier_id": "xxxxx-xx-1",
"url": "/testers/xxxxx-xx-1",
"collection": [
{
"text": "How hot will it be today?",
"top_class": "temperature",
"classes": [
{
"class_name": "temperature",
"confidence": 0.993
},
{
"class_name": "conditions",
"confidence": 0.006
}
]
},
{
"text": "Is it hot outside?",
"top_class": "temperature",
"classes": [
{
"class_name": "temperature",
"confidence": 1.0
},
{
"class_name": "conditions",
"confidence": 0.0
}
]
}
]
}
Current Output

Code and undesired output

I tried json_normalize, however, it's giving duplicates.
How can I convert this Jason file to Pandas DataFrame?
The records for each collection should be expanded wide, not long.