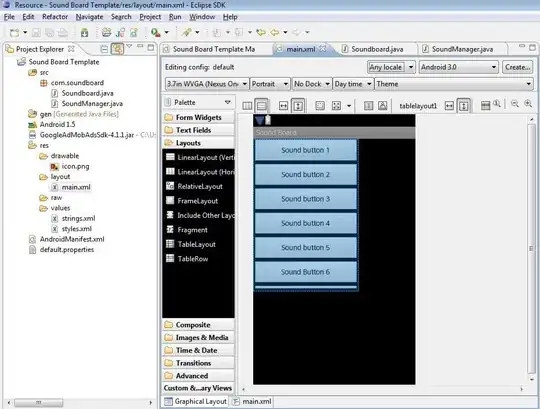
One methood you could try is to create spark dataframe first and then make a table out of it. Giving example for a hypothetical case below using pyspark where delimiters were | and -
BEWARE: we are using split and it means that it will split everything, e.g. 2000-12-31 is a value yest it will be split. Therefor we should be very sure that no such case would ever occur in data. As general advice, one should never accept these types of files as there are accidents waiting to happen.
How sample data looks: in this case we have 2 files in our directory with | and - occurring randomly as delimiters
# Create RDD. Basically read as simple text file.
# sc is spark context
rddRead = sc.textFile("/mnt/adls/RI_Validation/ReadMulktipleDelimerFile/Sample1/")
rddRead.collect() # For debugging

import re # Import for usual python regex
# Create another rdd using simple string opertaions. This will be similar to list of lists.
# Give regex expression to split your string based on anticipated delimiters (this could be dangerous
# if those delimiter occur as part of value. e.g.: 2021-12-31 is a single value in reality.
# But this a price we have to pay for not having good data).
# For each iteration, k represents 1 element which would eventually become 1 row (e.g. A|33-Mech)
rddSplit = rddRead.map(lambda k: re.split("[|-]+", k)) # Anticipated delimiters are | OR - in this case.
rddSplit.collect() # For debugging
# This block is applicable only if you have headers
lsHeader = rddSplit.first() # Get First element from rdd as header.
print(lsHeader) # For debugging
print()
# Remove rows representing header. (Note: Have assumed name of all columns in
# all files are same. If not, then will have to filter by manually specifying
#all of them which would be a nightmare from pov of good code as well as maintenance)
rddData = rddSplit.filter(lambda x: x != lsHeader)
rddData.collect() # For debugging
# Convert rdd to spark dataframe
# Utilise the header we got in earlier step. Else can give our own headers.
dfSpark = rddData.toDF(lsHeader)
dfSpark.display() # For debugging