I want to train a multi-out and multi-class classification model from scratch (using custom fit()). And I want some advice. For the sake of learning opportunity, here I'm demonstrating the whole scenario in more detail. Hope it may come helpful to anyone.
Data Set and Goal
I'm using data from here; It's a Bengali handwritten character recognition challenge, each of the samples has 3 mutually related output along with multiple classes of each. Please see the figure below:
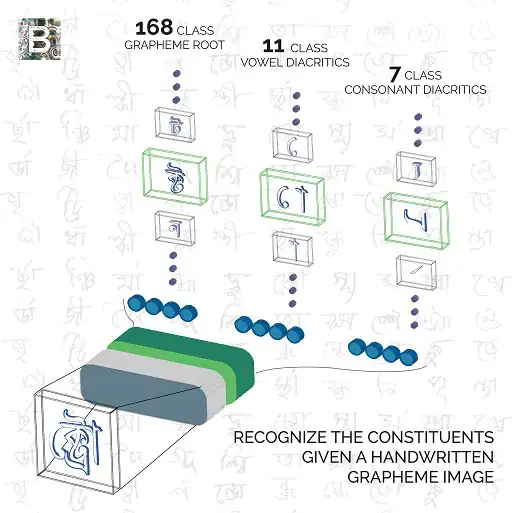
In the above figure, as you can see, the ক্ট্রো is consist of 3 component (ক্ট , ো , ্র), namely Grapheme Root, Vowel Diactrics and Consonant Diacritics respectively and together they're called Grapheme. Again the Grapheme Root also has 168 different categories and also same as others (11 and 7). The added complexity results in ~13,000 different grapheme variations (compared to English’s 250 graphemic units).
The goal is to classify the Components of the Grapheme in each image.
Initial Approach (and no issue with it)
I implemented a training pipeline over here, where it's demonstrated using old keras (not tf.keras) with its a convenient feature such as model.compile, callbacks etc. I defined a custom data generator and defined a model architecture something like below.
input_tensor = Input(input_dim)
curr_output = base_model(input_tensor)
oputput1 = Dense(168, activation='softmax', name='gra') (curr_output)
oputput2 = Dense(11, activation='softmax', name='vow') (curr_output)
oputput3 = Dense(7, activation='softmax', name='cons') (curr_output)
output_tensor = [oputput1, oputput2, oputput3]
model = Model(input_tensor, output_tensor)
And compile the model as follows:
model.compile(
optimizer = Adam(learning_rate=0.001),
loss = {'gra' : 'categorical_crossentropy',
'vow' : 'categorical_crossentropy',
'cons': 'categorical_crossentropy'},
loss_weights = {'gra' : 1.0,
'vow' : 1.0,
'cons': 1.0},
metrics={'gra' : 'accuracy',
'vow' : 'accuracy',
'cons': 'accuracy'}
)
As you can see I can cleary control each of the outputs with specific loss, loss_weights, and accuracy. And using the .fit() method, it's feasible to use any callbacks function for the model.
New Approach (and some issue with it)
Now, I want to re-implement it with the new feature of tf.keras. Such as model subclassing and custom fit training. However, no change in the data loader. The model is defined as follows:
def __init__(self, dim):
super(Net, self).__init__()
self.efnet = EfficientNetB0(input_shape=dim,
include_top = False,
weights = 'imagenet')
self.gap = KL.GlobalAveragePooling2D()
self.output1 = KL.Dense(168, activation='softmax', name='gra')
self.output2 = KL.Dense(11, activation='softmax', name='vow')
self.output3 = KL.Dense(7, activation='softmax', name='cons')
def call(self, inputs, training=False):
x = self.efnet(inputs)
x = self.gap(x)
y_gra = self.output1(x)
y_vow = self.output2(x)
y_con = self.output3(x)
return [y_gra, y_vow, y_con]
Now the issue mostly I'm facing is to correctly define the metrics, loss, and loss_weights function for each of my outputs. However, I started as follows:
optimizer = tf.keras.optimizers.Adam(learning_rate=0.05)
loss_fn = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
train_acc_metric = tf.keras.metrics.Accuracy()
@tf.function
def train_step(x, y):
with tf.GradientTape(persistent=True) as tape:
logits = model(x, training=True) # Logits for this minibatch
train_loss_value = loss_fn(y, logits)
grads = tape.gradient(train_loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
train_acc_metric.update_state(y, logits)
return train_loss_value
for epoch in range(2):
# Iterate over the batches of the dataset.
for step, (x_batch_train, y_batch_train) in enumerate(train_generator):
train_loss_value = train_step(x_batch_train, y_batch_train)
# Reset metrics at the end of each epoch
train_acc_metric.reset_states()
Apart from the above setup, I've tried other many ways to handle such problem cases though. For example, I defined 3 loss function and also 3 metrics as well but things are not working properly. The loss/acc became nan type stuff.
Here are my few straight queries in such case:
- how to define
loss,metricsandloss_weights - how to efficient use of all
callbacksfeatures
And just sake of learning opportunity, what if it has additionally regression type output (along with the rest 3 multi-out, so that total 4); how to deal all of them in custom fit? I've visited this SO, gave some hint for a different type of output (classification + regression).