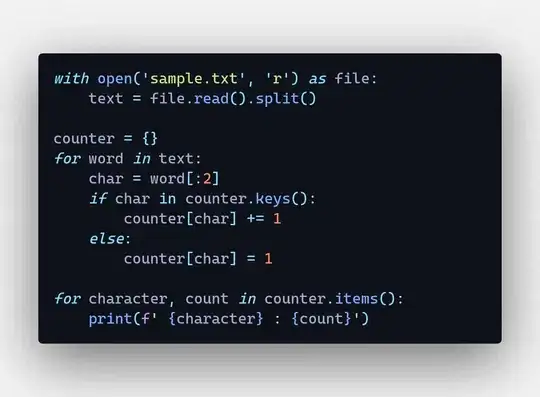
The program I wrote is terrible so if anyone can make a different py and give me some pointers well thanks a bunch!
What I would like help on is to print only the first two characters of a word and if those same characters repeat hold them to a count. It's like a Zipf distribution but for the first two letters for every word. The example is how I would like the output. Here is an example from this text and its for show!
text file = "Here is an example from this text and its for show!"
an 2
He 1
is 1
ex 1
fr 1
th 1
te 1
it 1
fo 1
sh 1
total 11
file = open("C:\python37\paradise.txt", 'r')
while 1:
# read by character
char = file.read(2)
if not char:
break
print(char)
file.close()