Your problem can be transposed, so you only need 3 keys in your cache and a lot less runtime to boot. Less distinct keys means better caching (A smarter person than me may still find a cheaper solution).
Let's view the partitions as sets. The elements of each set shall be ordered (ascending).
You have already done this implicitly, when you stated the expected results for sum := 15, k := 4, m:= 10 as [1, 2, 3, 9]; [1, 2, 4, 8] ....
The restrictions you defined for the partitions are:
- exactly
k elements per set
- max
m as element
- distinct values
- non-zero positive integers
The restriction of distinction is actually a bit bothersome, so we will lift it.
For that, we need to transform the problem a bit. Because the elements of your set are ascending (and distinct), we know, that the minimum value of each element is an ascending sequence (if we ignore that the sum must be sum), so the minia are: [1, 2, 3, ...].
If m were for example less than k, then the number of possible partitions would always be zero. Likewise, if the sum of [1, 2, 3, ... k] is more than sum, then you also have zero results. We exclude these edge cases at the beginning, to make sure the transformation is legal.
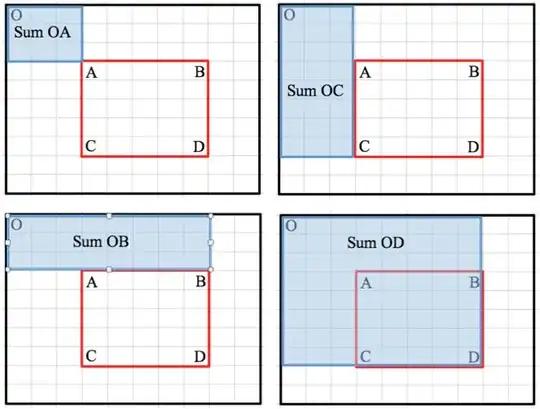
Let us look at a geometric representation of a 'legal partition' and how we want to transform it. We have k columns, m rows and sum squares are filled blue (either light or dark blue).
The red and dark blue squares are irrelevant, as we already know, the dark blue squares must always be filled, and the red ones must always be empty. Therefore we can exclude them from our calculation and assume their respective states as we go along. The resulting box is represented on the right side. Every column was 'shifted down' by it's position, and the red and dark blue areas are cut off.
We now have a smaller overall box and a column can now be empty (and we may have the same number of blue boxes among neighboring columns).
Algorithmically the transformation now works like this:
For every element in a legal partition, we subtract it's position (starting at 1). So for
[1, 2, 4, 8] we get [0, 0, 1, 4]. Furthermore, we have to adapt our bounds (sum and m) accordingly:
// from the sum, we subtract the sum of [1, 2, 3, ... k], which is (k * (k + 1) / 2)
sum_2 = sum - (k * (k + 1) / 2)
// from m we subtract the maximum position (which is k)
m_2 = m - k
Now we have transposed our partitioning problem into another partitioning problem, one that does not have the restriction of distinct elements! Also, this partition can contain element 0, which our original could not. (We keep the internal ascending order).
Now we need to refine the recursion a bit. If we know the elements are ascending, not necessariely distinct and always less-equal to m_2, then we have bound the possible elements to a range. Example:
[0, 1, 3, n1, n2]
=> 3 <= n1 <= m_2
=> 3 <= n2 <= m_2
Because we know that n1 and n2 in the example are 3 or greater, when calling the recursion, we can also instead reduce them both by 3 and reduce sum_2 by 2 * 3 (one is the number of 'open' elements, one is the value of the last 'fixed' element). This way, what we pass in the recursion does not have an upper and a lower bound, but only an upper bound, which is what we had before (m).
Because of this, we can toss 1 value of your cache key: start. Instead we now only have 3: sum, m and k, when solving this reduced problem.
The following implementation works to this effect:
@Test
public void test() {
calcNumRIPdistinctElementsSpecificKmaxM(600, (short) 25, (short) 200);
}
public BigInteger calcNumRIPdistinctElementsSpecificKmaxM(int sum, short k, short m) {
// If the biggest allowed number in a partition is less than the number of parts, then
// they cannot all be distinct, therefore we have zero results.
if (m < k) {
return BigInteger.ZERO;
}
// If the sum of minimum element-values for k is less than the expected sum, then
// we also have no results.
final int v = ((k * ((int) k + 1)) / 2);
if (sum < v) {
return BigInteger.ZERO;
}
// We normalize the problem by lifting the distinction restriction.
final Cache cache = new Cache();
final int sumNorm = sum - v;
final short mNorm = (short) (m - k);
BigInteger result = calcNumRIPspecificKmaxM(sumNorm, k, mNorm, cache);
System.out.println("Calculation (n=" + sum + ", k=" + k + ", m=" + m + ")");
System.out.println("p = " + result);
System.out.println("entries = " + cache.getNumEntries());
System.out.println("c-rate = " + cache.getCacheRate());
return result;
}
public BigInteger calcNumRIPspecificKmaxM(int sum, short k, short m, Cache cache) {
// We can improve cache use by standing the k*m-rectangle upright (k being the 'bottom').
if (k > m) {
final short c = k;
k = m;
m = c;
}
// If the result is trivial, we just calculate it. This is true for k < 3
if (k < 3) {
if (k == 0) {
return sum == 0 ? BigInteger.ONE : BigInteger.ZERO;
} else if (k == 1) {
return sum <= m ? BigInteger.ONE : BigInteger.ZERO;
} else {
final int upper = Math.min(sum, m);
final int lower = sum - upper;
if (upper < lower) {
return BigInteger.ZERO;
}
final int difference = upper - lower;
final int numSubParts = difference / 2 + 1;
return BigInteger.valueOf(numSubParts);
}
}
// If k * m / 2 < sum, we can 'invert' the sub problem to reduce the number of keys further.
sum = Math.min(sum, k * m - sum);
// If the sum is less than m and maybe even k, we can reduce the box. This improves the cache size even further.
if (sum < m) {
m = (short) sum;
if (sum < k) {
k = (short) sum;
if (k < 3) {
return calcNumRIPspecificKmaxM(sum, k, m, cache);
}
}
}
// If the result is non-trivial, we check the cache or delegate.
final Triple<Short, Short, Integer> key = Triple.of(k, m, sum);
final BigInteger cachedResult = cache.lookUp(key);
if (cachedResult != null) {
return cachedResult;
}
BigInteger current = BigInteger.ZERO;
// i = m is reached in case the result is an ascending stair e.g. [1, 2, 3, 4]
for (int i = 0; i <= m; ++i) {
final int currentSum = sum - (i * k);
if (currentSum < 0) {
break;
}
short currentK = (short) (k - 1);
short currentM = (short) (m - i);
current = current.add(calcNumRIPspecificKmaxM(currentSum, currentK, currentM, cache));
}
// We cache this new result and return it.
cache.enter(key, current);
return current;
}
public static class Cache {
private final HashMap<Triple<Short, Short, Integer>, BigInteger> map = new HashMap<>(1024);
private long numLookUps = 0;
private long numReuse = 0;
public BigInteger lookUp(Triple<Short, Short, Integer> key) {
++numLookUps;
BigInteger value = map.get(key);
if (value != null) {
++numReuse;
}
return value;
}
public void enter(Triple<Short, Short, Integer> key, BigInteger value) {
map.put(key, value);
}
public double getCacheRate() {
return (double) numReuse / map.size();
}
public int getNumEntries() {
return map.size();
}
public long numLookUps() {
return numLookUps;
}
public long getNumReuse() {
return numReuse;
}
}
Note: I used apache-common's Triple-class as key here, to spare the implementation of an explicit key-class, but this is not an optimization in runtime, it just saves code.
Edit: Beside a fix to a problem found by @MBo (thank you), I added a few shortcuts to reach the same result. The algorithm now performs even better, and the cache (reuse) rate is better. Maybe this will satisfy your requirements?
The optimizations explained (they are only applicable after the above mentioned transposition of the problem):
- If
k > m, we can 'flip' the rectangle upright, and still get the same result for the number of legal partitions. This will map some 'lying' configurations into 'upright' configurations and reduce the overall amount of different keys.
- If the number of squares in the rectangle is larger than the number of 'empty spaces', we can consider the 'empty spaces' as squares instead, which will map another bunch of keys together.
- If
sum < k and/or sum < m, we can reduce k and/or m to sum, and still get the same number of partitions. (this is the most impacting optimization, as it often skips multiple redundant interim steps and frequently reaches m = k = sum)