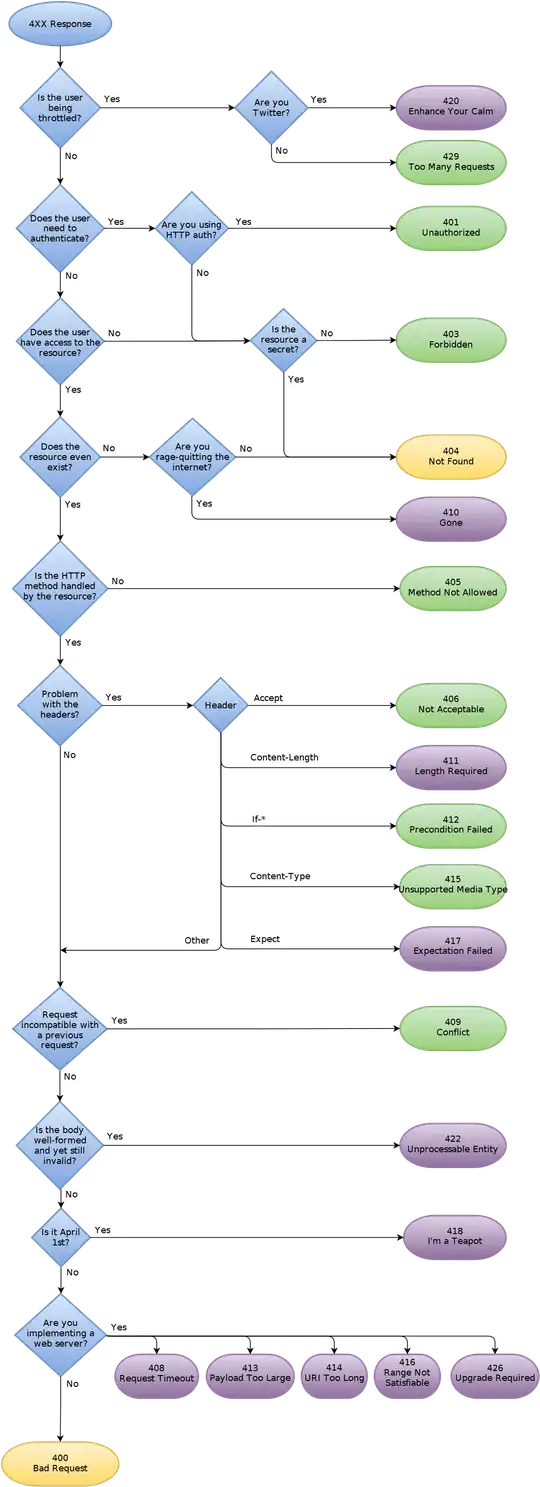
Solution
You can do it in a single line using regex + pandas method-chaining as follows. I have broken it into multiple lines for better readability. For more details please see Section C below. ⭐
Note: Sections A and B use the data from section D, which the OP had shared earlier. Later the data in the question was changed and Section C gives the solution to this use-case.
Regex Examples:
In the interest of explaining the how regex-pattern works, please take a look at the following three examples:
- example-1: I have used this regex pattern in Section-A. This will help work given we have the data as given in Section-D.
- example-2: This is an improved version of the regex in example-1. I have used this regex pattern in Section-B and C.
- example-3: Finally, this example illustrates how the pattern used in example-2 could skip unwanted text and only pick intended text-parrens.
# without alphabetically ordering the columns
(df[COLUMN_NAME] ## access the "data"-column
.fillna('0xUNKN') ## replace nan values with 0xUNKN
.str.findall(pat) ## use regex to extract patterns
.apply(lambda x: dict((k, v) for v, k in x if (int(v)!=0))) ## row-wise create dict to construct final {column: count} structure
.apply(pd.Series) ## use dict to create columns
.fillna(0) ## replace NaN values with 0
)
A. Each operation with explanation
Here I explain what each operation does and finally reorder the columns alphabetically.
Regex Explanation: example-1
Find a detailed explanation of how the regex (\d+)x(\w+)\s*,\s*(\d+)x(\w+) works to extract various intended parts from the input text here: example-1.
# NOTE: I am using the dataframe that I created in
# the Dummy Data section "below"
df2 = (df.data # access the "data"-column
.str.findall('(\d+)x(\w+)\s*,\s*(\d+)x(\w+)') # use regex to extract patterns
.explode() # explode each rows' list into columns
.apply(lambda x: {x[1]: x[0], x[3]: x[2]}) # row-wise create dict to construct final {column: count} structure
.apply(pd.Series) # expand each cell into columns
.fillna(0) # replace NaN values with 0
)
df2 = df2.reindex(sorted(df2.columns), axis=1) # alphabetically reorder columns
print(df2)
Output:
AAAA BBBB CCCC
0 1 1 0
1 1 2 0
2 1 0 1
B. A more generic solution
If you have more than two types per line (say, AAAA, BBBB, CCCC), the following solution will work in that case as well.
Regex Explanation: example-2
Find a detailed explanation of how the regex (?:\s*(\d+)x(\w+)\s*)+ works to extract various intended parts from the input text here: example-2.

Code
import pandas as pd
## Dummy Data
data = [
'1xAAAA,2xBBBB,3xDDDD',
'1xBBBB,1xAAAA,6xEEEE',
'1xAAAA,1xCCCC,3xDDDD',
]
df = pd.DataFrame(data, columns=['data'])
print('\n Input:')
print(df)
## Output:
# data
# 0 1xAAAA,2xBBBB,3xDDDD
# 1 1xBBBB,1xAAAA,6xEEEE
# 2 1xAAAA,1xCCCC,3xDDDD
## Process DataFrame
# define regex pattern
pat = '(?:\s*(\d+)x(\w+)\s*)+' # regex search pattern
# create dataframe in the expected format
df2 = (df.data ## access the "data"-column
.str.findall(pat) ## use regex to extract patterns
.apply(lambda x: dict((k, v) for v, k in x)) ## row-wise create dict to construct final {column: count} structure
.apply(pd.Series) ## use dict to create columns
.fillna(0) ## replace NaN values with 0
)
df2 = df2.reindex(sorted(df2.columns), axis=1) ## alphabetically reorder columns
print('\n Output:')
print(df2)
## Output:
# AAAA BBBB CCCC DDDD EEEE
# 0 1 2 0 3 0
# 1 1 1 0 0 6
# 2 1 0 1 3 0
C. Specific Example for Data Shared by the OP ⭐
Here is an example on the specific sample-data shared by the OP. This specific use-case shows the presence of nan values in the dataframe. As a strategy to use the previously suggested solution with minimal modification, you could just replace those nan values with a string 0xUNKN and then filter the results that do not start with a 0.
import pandas as pd
COLUMN_NAME = 'SmVariant'
## Dummy Data
data = [
'1xFBBC', float('nan'),
'2xFBBA', '5xABIA',
'2xFBBC, 1xFBBA',
'1xFBBA', '4xABIA',
'1xFBBA, 1xFBBC',
float('nan'), '1xFBBA',
'3xFBBA, 1xFBBC',
]
df = pd.DataFrame({COLUMN_NAME: data})
print('\n Input:')
print(df)
## Output:
# SmVariant
# 0 1xFBBC
# 1 NaN
# 2 2xFBBA
# 3 5xABIA
# 4 2xFBBC, 1xFBBA
# 5 1xFBBA
# 6 4xABIA
# 7 1xFBBA, 1xFBBC
# 8 NaN
# 9 1xFBBA
# 10 3xFBBA, 1xFBBC
## Process DataFrame
# define regex pattern
pat = '(?:\s*(\d+)x(\w+)\s*)+' # regex search pattern
# create dataframe in the expected format
df2 = (df[COLUMN_NAME] ## access the "data"-column
.fillna('0xUNKN') ## replace nan values with 0xUNKN
.str.findall(pat) ## use regex to extract patterns
.apply(lambda x: dict((k, v) for v, k in x if (int(v)!=0))) ## row-wise create dict to construct final {column: count} structure
.apply(pd.Series) ## use dict to create columns
.fillna(0) ## replace NaN values with 0
)
df2 = df2.reindex(sorted(df2.columns), axis=1) ## alphabetically reorder columns
print('\n Output:')
print(df2)
## Output:
# ABIA FBBA FBBC
# 0 0 0 1
# 1 0 0 0
# 2 0 2 0
# 3 5 0 0
# 4 0 1 2
# 5 0 1 0
# 6 4 0 0
# 7 0 1 1
# 8 0 0 0
# 9 0 1 0
# 10 0 3 1
D. Dummy Data
import pandas as pd
data = {
'1xAAAA,2xBBBB',
'1xBBBB,1xAAAA',
'1xAAAA,1xCCCC',
}
df = pd.DataFrame(data, columns=['data'])
print(df)
## Output:
# data
# 0 1xBBBB,1xAAAA
# 1 1xAAAA,2xBBBB
# 2 1xAAAA,1xCCCC
References
Re-ordering columns in pandas dataframe based on column name [duplicate]
pandas.DataFrame.explode
Expand Cells Containing Lists Into Their Own Variables In Pandas